数据准备过程中如何创建虚拟变量
2020-01-14
原文地址:https://www.marsja.se/how-to-use-pandas-get_dummies-to-create-dummy-variables-in-python/
作者:Erik Marsja
翻译:老齐
在本文中,我们将学习如何使用Pandas的get_dummies()方法创建虚拟变量,这是数据准备中经常要执行的操作。虚拟变量(注: dummy variable,也有人翻译为:哑变量、伪变量)通常用于统计分析以及更简单的描述性统计。
读者关注微信公众号:老齐教室,并回复信息:姓名+手机号+‘案例’,即可加入在线实验平台,获得本文的代码和数据。
用于回归分析的虚拟编码
有一种统计分析需要在回归分析中创建虚拟变量。事实上,回归分析需要数值型变量,这意味着无论是做研究还是分析数据,当我们希望在回归模型中包含一个分类型变量时,都需要一些补充步骤来使结果具有可解释性。

上面的表格中,分类型特征被重新编码为一组单独的虚拟变量,这个过程称之为“虚拟编码”,它涉及一个对比矩阵的表。某些软件可以自动实现虚拟编码。
什么是分类特征?
在统计学中,分类型特征接受一个有限的、通常是固定数量的可能值。此外,这些特征通常给每个样本或观察分配一个特定的类别,例如,性别是一个分类变量。
关于特征(变量)的类型,请参阅《数据准备和特征工程》(电子工业出版社出版》(预计2020年3月发行)

在下面的内容中,我们将使用薪资数据集,其中包含2008-09年美国大学助理教授、副教授和教授九个月的学术薪资。
导入数据
首先读入数据,这是毫无疑问的。(数据已经放到本文指定的实验平台,请关注微信公众号,并按照前文提示中的方式获取)
1 | import pandas as pd |
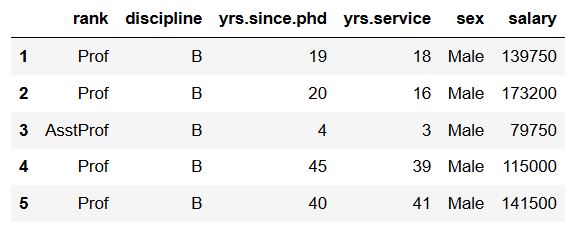
当然,数据可以存储在多个不同的文件类型中,可以将数据存储在.xlsx、SPSS、SAS或STATA文件中。
创建虚拟变量
在本节中,我们将使用pandas的get_dummies创建虚拟变量。首先,我们对分类型特征sex创建虚拟变量,它是有两个类型数据的变量。
其次,我们还将生成带有变量rank的虚拟变量。也就是说,在这个虚拟的编码示例中,我们将使用具有三种类型数据的变量。
get_dummies方法的详细调用方式如下图所示:

图中所示的参数prefix_sep,可以更改虚拟变量名中与前缀的分隔符。
第一个示例
如下代码所示,得到两个名为Female和Male的新特征。
1 | pd.get_dummies(df[‘sex’]).head() |
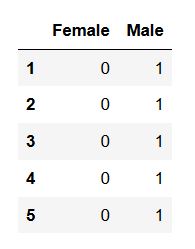
在上面的代码中,我们打印了前5行。下面使用参数columns,以一个列表为其值,以便根据列表所含的特征创建虚拟变量。
更多示例
1 | df_dummies = pd.get_dummies(df, columns=['sex']) |

输出显示,get_dummies自动添加以“sex”作为前缀,下划线_作为前缀分隔符的新变量。但是,如果我们想更改前缀和前缀分隔符,可以如此设置参数:
1 | df_dummies = pd.get_dummies(df, prefix='Gender', prefix_sep='.', columns=['sex']) |
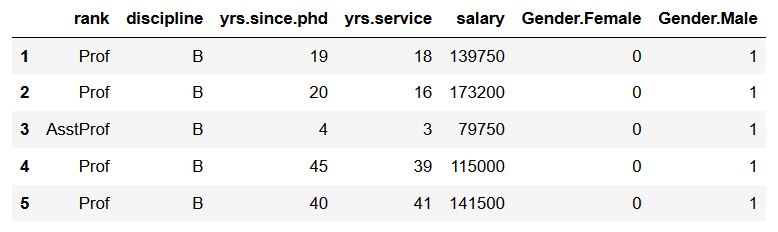
从虚拟变量名称中移除前缀和分隔符
在下面的代码中,我们将设置参数prefix_sephe prefix的值设置为空字符串,便将特征名中的前缀和分隔符去掉。
1 | df_dummies = pd.get_dummies(df, prefix='', prefix_sep='', |
创建三类型特征的虚拟变量
特征rank具有三种不同类型的数据,对它创建虚拟变量。下面的代码与第一个示例中的相同。
1 | pd.get_dummies(df['rank']).head() |
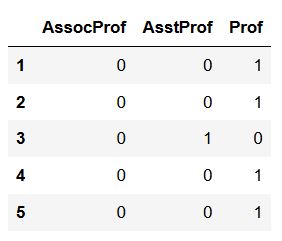
也就是说,我们列作为唯一参数,然后只得到一个带有3个列的DataFrame。
当然,我们希望将虚拟变量与原数据放在同一DataFrame中,还是用columns参数,以列表的方式声明特征:
1 | df_dummies = pd.get_dummies(df, columns=['rank']) |

在上图中,我们可以看到Pandas get_dummies() 添加了“rank”作为前缀,下划线作为前缀分隔符。接下来,我们将把前缀和分隔符改为“Rank”(大写)和“.”(点)。
1 | df_dummies = pd.get_dummies(df, prefix='Rank', prefix_sep='.', |
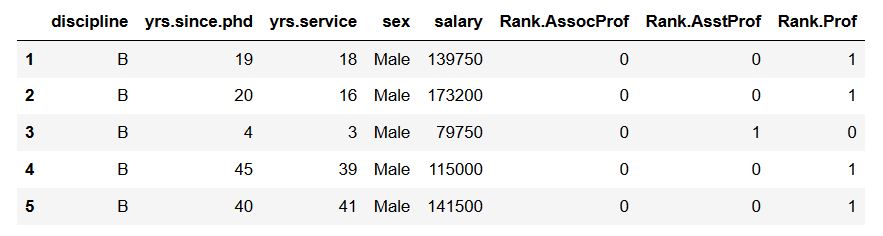
如果不需要有前缀或分隔符,只需在prefix和prefix_sep参数中添加空字符串:
1 | df_dummies = pd.get_dummies(df, prefix='', prefix_sep='', |
为多列创建虚拟变量
在最后一个示例中,我们将要对两列进行虚拟编码。具体来说,就是添加一个包含两个分类型特征的列表,实际上,这非常简单,我们可以按照上面的示例代码进行操作:
1 | df_dummies = pd.get_dummies(df, prefix='', prefix_sep='', |
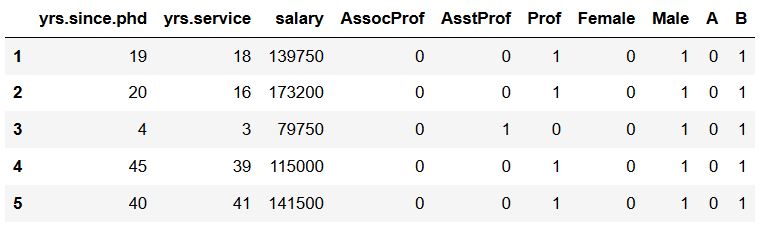
如果想添加更多的列,可以将其添加column参数的列表中,更多示例,参见在线平台的案例(注: 关注微信公众号:老齐教室,并按照下面的格式回复信息:姓名+手机号+‘案例’,即可加入在线实验平台,获得本文的代码和数据《案例:创建虚拟变量》)。
结论
在本文中,我们学习了如何使用Pandas的get_dummies() 方法创建虚拟变量。此外,scikit-learn中也提供了类似的方法,即OneHot编码,具体请参阅《数据准备和特征工程》相关章节的阐述。
关注微信公众号:老齐教室。读深度文章,得精湛技艺,享绚丽人生。
若你觉得我的文章对你有帮助,欢迎点击上方按钮对我打赏

关注微信公众号,读文章、听课程,提升技能