import numpy as np import pickle from pathlib import Path
# Path to the unzipped CIFAR data data_dir = Path("data/cifar-10-batches-py/")
# Unpickle function provided by the CIFAR hosts def unpickle(file): with open(file, "rb") as fo: dict = pickle.load(fo, encoding="bytes") return dict
images, labels = [], [] for batch in data_dir.glob("data_batch_*"): batch_data = unpickle(batch) for i, flat_im in enumerate(batch_data[b"data"]): im_channels = [] # Each image is flattened, with channels in order of R, G, B for j in range(3): im_channels.append( flat_im[j * 1024 : (j + 1) * 1024].reshape((32, 32)) ) # Reconstruct the original image images.append(np.dstack((im_channels))) # Save the label labels.append(batch_data[b"labels"][i])
def store_single_disk(image, image_id, label): """ Stores a single image as a .png file on disk. Parameters: --------------- image image array, (32, 32, 3) to be stored image_id integer unique ID for image label image label """ Image.fromarray(image).save(disk_dir / f"{image_id}.png")
with open(disk_dir / f"{image_id}.csv", "wt") as csvfile: writer = csv.writer( csvfile, delimiter=" ", quotechar="|", quoting=csv.QUOTE_MINIMAL ) writer.writerow([label])
class CIFAR_Image: def __init__(self, image, label): # Dimensions of image for reconstruction - not really necessary # for this dataset, but some datasets may include images of # varying sizes self.channels = image.shape[2] self.size = image.shape[:2]
self.image = image.tobytes() self.label = label
def get_image(self): """ Returns the image as a numpy array. """ image = np.frombuffer(self.image, dtype=np.uint8) return image.reshape(*self.size, self.channels)
def store_single_lmdb(image, image_id, label): """ Stores a single image to a LMDB. Parameters: --------------- image image array, (32, 32, 3) to be stored image_id integer unique ID for image label image label """ map_size = image.nbytes * 10
# Create a new LMDB environment env = lmdb.open(str(lmdb_dir / f"single_lmdb"), map_size=map_size)
# Start a new write transaction with env.begin(write=True) as txn: # All key-value pairs need to be strings value = CIFAR_Image(image, label) key = f"{image_id:08}" txn.put(key.encode("ascii"), pickle.dumps(value)) env.close()
def store_single_hdf5(image, image_id, label): """ Stores a single image to an HDF5 file. Parameters: --------------- image image array, (32, 32, 3) to be stored image_id integer unique ID for image label image label """ # Create a new HDF5 file file = h5py.File(hdf5_dir / f"{image_id}.h5", "w")
# Create a dataset in the file dataset = file.create_dataset( "image", np.shape(image), h5py.h5t.STD_U8BE, data=image ) meta_set = file.create_dataset( "meta", np.shape(label), h5py.h5t.STD_U8BE, data=label ) file.close()
for method in ("disk", "lmdb", "hdf5"): t = timeit( "_store_single_funcs[method](image, 0, label)", setup="image=images[0]; label=labels[0]", number=1, globals=globals(), ) store_single_timings[method] = t print(f"Method: {method}, Time usage: {t}")
def store_many_disk(images, labels): """ Stores an array of images to disk Parameters: --------------- images images array, (N, 32, 32, 3) to be stored labels labels array, (N, 1) to be stored """ num_images = len(images)
# Save all the images one by one for i, image in enumerate(images): Image.fromarray(image).save(disk_dir / f"{i}.png")
# Save all the labels to the csv file with open(disk_dir / f"{num_images}.csv", "w") as csvfile: writer = csv.writer( csvfile, delimiter=" ", quotechar="|", quoting=csv.QUOTE_MINIMAL ) for label in labels: # This typically would be more than just one value per row writer.writerow([label])
def store_many_lmdb(images, labels): """ Stores an array of images to LMDB. Parameters: --------------- images images array, (N, 32, 32, 3) to be stored labels labels array, (N, 1) to be stored """ num_images = len(images)
map_size = num_images * images[0].nbytes * 10
# Create a new LMDB DB for all the images env = lmdb.open(str(lmdb_dir / f"{num_images}_lmdb"), map_size=map_size)
# Same as before — but let's write all the images in a single transaction with env.begin(write=True) as txn: for i in range(num_images): # All key-value pairs need to be Strings value = CIFAR_Image(images[i], labels[i]) key = f"{i:08}" txn.put(key.encode("ascii"), pickle.dumps(value)) env.close()
def store_many_hdf5(images, labels): """ Stores an array of images to HDF5. Parameters: --------------- images images array, (N, 32, 32, 3) to be stored labels labels array, (N, 1) to be stored """ num_images = len(images)
# Create a new HDF5 file file = h5py.File(hdf5_dir / f"{num_images}_many.h5", "w")
# Create a dataset in the file dataset = file.create_dataset( "images", np.shape(images), h5py.h5t.STD_U8BE, data=images ) meta_set = file.create_dataset( "meta", np.shape(labels), h5py.h5t.STD_U8BE, data=labels ) file.close()
for cutoff in cutoffs: for method in ("disk", "lmdb", "hdf5"): t = timeit( "_store_many_funcs[method](images_, labels_)", setup="images_=images[:cutoff]; labels_=labels[:cutoff]", number=1, globals=globals(), ) store_many_timings[method].append(t)
# Print out the method, cutoff, and elapsed time print(f"Method: {method}, Time usage: {t}")
def plot_with_legend( x_range, y_data, legend_labels, x_label, y_label, title, log=False ): """ Displays a single plot with multiple datasets and matching legends. Parameters: -------------- x_range list of lists containing x data y_data list of lists containing y values legend_labels list of string legend labels x_label x axis label y_label y axis label """ plt.style.use("seaborn-whitegrid") plt.figure(figsize=(10, 7))
if len(y_data) != len(legend_labels): raise TypeError( "Error: number of data sets does not match number of labels." )
all_plots = [] for data, label in zip(y_data, legend_labels): if log: temp, = plt.loglog(x_range, data, label=label) else: temp, = plt.plot(x_range, data, label=label) all_plots.append(temp)
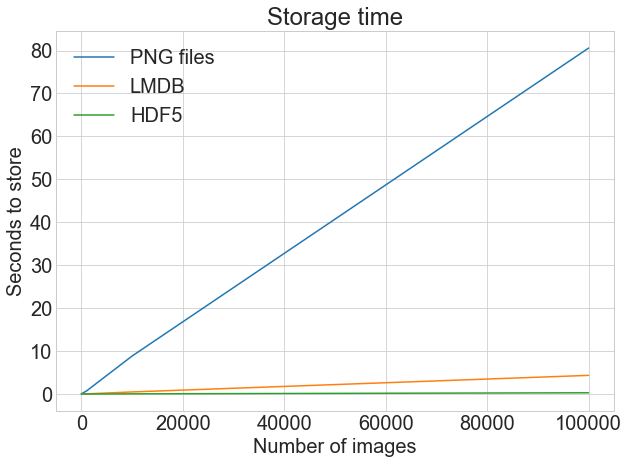
# Getting the store timings data to display disk_x = store_many_timings["disk"] lmdb_x = store_many_timings["lmdb"] hdf5_x = store_many_timings["hdf5"]
plot_with_legend( cutoffs, [disk_x, lmdb_x, hdf5_x], ["PNG files", "LMDB", "HDF5"], "Number of images", "Seconds to store", "Storage time", log=False, )
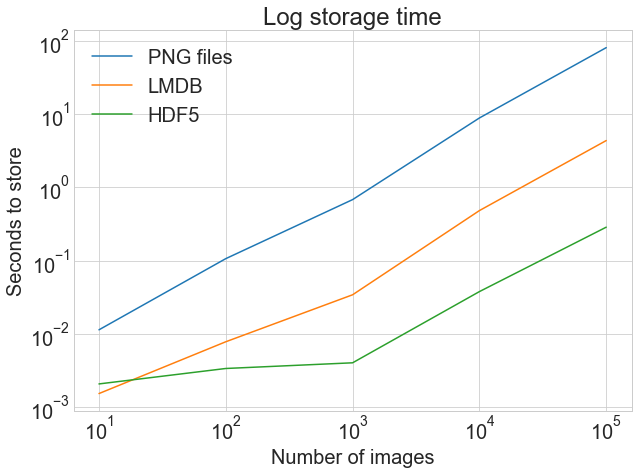
plot_with_legend( cutoffs, [disk_x, lmdb_x, hdf5_x], ["PNG files", "LMDB", "HDF5"], "Number of images", "Seconds to store", "Log storage time", log=True, )
def read_single_disk(image_id): """ Stores a single image to disk. Parameters: --------------- image_id integer unique ID for image Returns: ---------- image image array, (32, 32, 3) to be stored label associated meta data, int label """ image = np.array(Image.open(disk_dir / f"{image_id}.png"))
with open(disk_dir / f"{image_id}.csv", "r") as csvfile: reader = csv.reader( csvfile, delimiter=" ", quotechar="|", quoting=csv.QUOTE_MINIMAL ) label = int(next(reader)[0])
""" Stores a single image to LMDB. Parameters: --------------- image_id integer unique ID for image Returns: ---------- image image array, (32, 32, 3) to be stored label associated meta data, int label
def read_single_hdf5(image_id): """ Stores a single image to HDF5. Parameters: --------------- image_id integer unique ID for image
Returns: ---------- image image array, (32, 32, 3) to be stored label associated meta data, int label """ # Open the HDF5 file file = h5py.File(hdf5_dir / f"{image_id}.h5", "r+")
for method in ("disk", "lmdb", "hdf5"): t = timeit( "_read_single_funcs[method](0)", setup="image=images[0]; label=labels[0]", number=1, globals=globals(), ) read_single_timings[method] = t print(f"Method: {method}, Time usage: {t}")
def read_many_disk(num_images): """ Reads image from disk. Parameters: --------------- num_images number of images to read
Returns: ---------- images images array, (N, 32, 32, 3) to be stored labels associated meta data, int label (N, 1) """ images, labels = [], []
# Loop over all IDs and read each image in one by one for image_id in range(num_images): images.append(np.array(Image.open(disk_dir / f"{image_id}.png")))
with open(disk_dir / f"{num_images}.csv", "r") as csvfile: reader = csv.reader( csvfile, delimiter=" ", quotechar="|", quoting=csv.QUOTE_MINIMAL ) for row in reader: labels.append(int(row[0])) return images, labels
def read_many_lmdb(num_images): """ Reads image from LMDB. Parameters: --------------- num_images number of images to read
Returns: ---------- images images array, (N, 32, 32, 3) to be stored labels associated meta data, int label (N, 1) """ images, labels = [], [] env = lmdb.open(str(lmdb_dir / f"{num_images}_lmdb"), readonly=True)
# Start a new read transaction with env.begin() as txn: # Read all images in one single transaction, with one lock # We could split this up into multiple transactions if needed for image_id in range(num_images): data = txn.get(f"{image_id:08}".encode("ascii")) # Remember that it's a CIFAR_Image object # that is stored as the value cifar_image = pickle.loads(data) # Retrieve the relevant bits images.append(cifar_image.get_image()) labels.append(cifar_image.label) env.close() return images, labels
def read_many_hdf5(num_images): """ Reads image from HDF5. Parameters: --------------- num_images number of images to read
Returns: ---------- images images array, (N, 32, 32, 3) to be stored labels associated meta data, int label (N, 1) """ images, labels = [], []
# Open the HDF5 file file = h5py.File(hdf5_dir / f"{num_images}_many.h5", "r+")
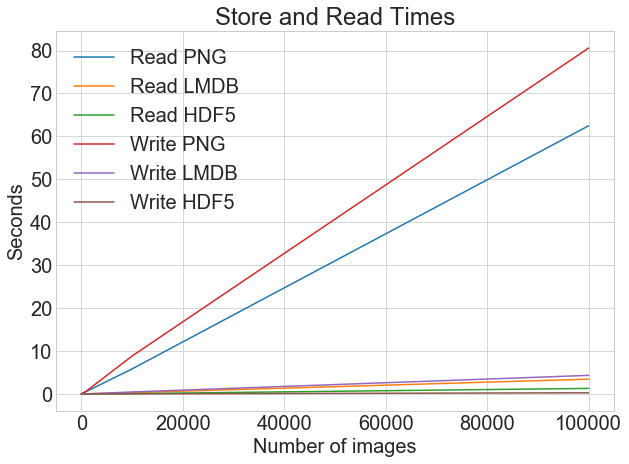
for cutoff in cutoffs: for method in ("disk", "lmdb", "hdf5"): t = timeit( "_read_many_funcs[method](num_images)", setup="num_images=cutoff", number=1, globals=globals(), ) read_many_timings[method].append(t)
# Print out the method, cutoff, and elapsed time print(f"Method: {method}, No. images: {cutoff}, Time usage: {t}")