特征为什么那么重要
2020-01-30
作者: Vinko Kodžoman
翻译:老齐
一个月以来,我一直在Kaggle研究Quora问答的机器学习竞赛,我注意到大家反复讨论的一个话题,现在想谈谈它,机器学习模型似乎有一个无法逾越的界限,虽然有的方法通常能够得到很好的结果,但是因为受限于数据的特征,导致它的上限无法突破。所以,我要强调,特征是非常重要的。
说明:2020年3月,电子工业出版社出版《数据准备和特征工程》,书中有专门章节讲解如何进行特征选择,也包括本文所介绍的依据特征重要度进行选择的方法。

数据探索
下面,我将使用Quora问答的数据集,此数据集中共有404290个问答,其中37%的问题在语义上相同的(“重复”),我们的目标是把它们找出来。
注:在《机器学习案例》中收录了本文项目,以及另外一个相关项目:识别重复问题,也是利用Quora问答数据完成。
开始,应该加载数据集,并对它进行探索:
1 | # Load the dataset |
重复和非重复问题对的示例如下所示。
| 问题1 | 问题2 | 是否重复 |
|---|---|---|
| What is the step by step guide to invest in share market in india? | What is the step by step guide to invest in share market? | 0 |
| How can I be a good geologist? | What should I do to be a great geologist? | 1 |
| How can I increase the speed of my internet connection while using a VPN? | How can Internet speed be increased by hacking through DNS? | 0 |
| How do I read and find my YouTube comments? | How do I read and find my YouTube comments? | 1 |
用词云来表示数据探索的结果,显示哪些词出现频率最高。词云是基于问答中的单词来创建的,如你所见,流行的词汇是正如你所预料,(如“best way”、“lose weight”、“difference”、“make money”等)。
此词云结果,参见《机器学习案例》中的项目“识别重复问题”。
现在我们对数据集的样子有了一些概念。
特征工程
我创建了24个特征,其中一些特征如下所示。所有代码都是借助机器学习库(pandas、sklearn、numpy)用Python编写的。
本文的代码已经收录到在线公开课程《机器学习案例》之中,关注本文的公众号,并回复:姓名+手机号+‘案例’,即可申请加入此课程。
- q1_word_num:问题1中的单词数
- q2_length:问题2中的字符数
- word_share:问题之间共享单词的比率
- same_first_word:如果两个问题的第一个单词相同,则为1,否则为0
1 | def word_share(row): |
模型性能
为了评估模型性能,我们首先将数据集划分为训练集和测试集,测试集含有总数据量的20%样本。
1 | X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) |
利用logloss函数对模型进行了评估,这是Kaggle中使用的同一度量标准。
$$logloss = \frac{1}{N} \displaystyle\sum_{i=1}^{N} \displaystyle\sum_{j=1}^{M} y_{i,j} * log(p_{i,j})$$
为了测试模型的所有特征,我们使用随机森林分类模型,它是一个强大的“开箱即用”集成分类器。不用进行超参数优化——它们可以保持不变,因为我们正在针对不同的特征集合测试模型的性能。一个简单的模型给出的logloss得分为0.62923,在我写这篇文章时,这个分数在总共1692个团队中排名第1371位。现在我们来看看做特征选择是否能帮助我们降低logloss。
1 | model = RandomForestClassifier(50, n_jobs=8) |

特征的重要性
为了获取特征的重要度,我们将使用一个默认进行特征选择的算法——XGBoost,它是Kaggle竞赛之王。如果你不使用神经网络,XGBoost可能是你的必须选择。XGBoost使用梯度上升来优化集成决策树算法,每棵树都包含若干节点,每个节点就是一个独立的特征。XGBoost决策树节点中的特征数与其对模型整体性能的影响成正比。
1 | model = XGBClassifier(n_estimators=500) |
如下图,我们看到一些特征根本没有用,而一些特性(如“word_share”)对性能影响很大。我们可以通过根据特征重要度生成特征子集,从而实现降维。
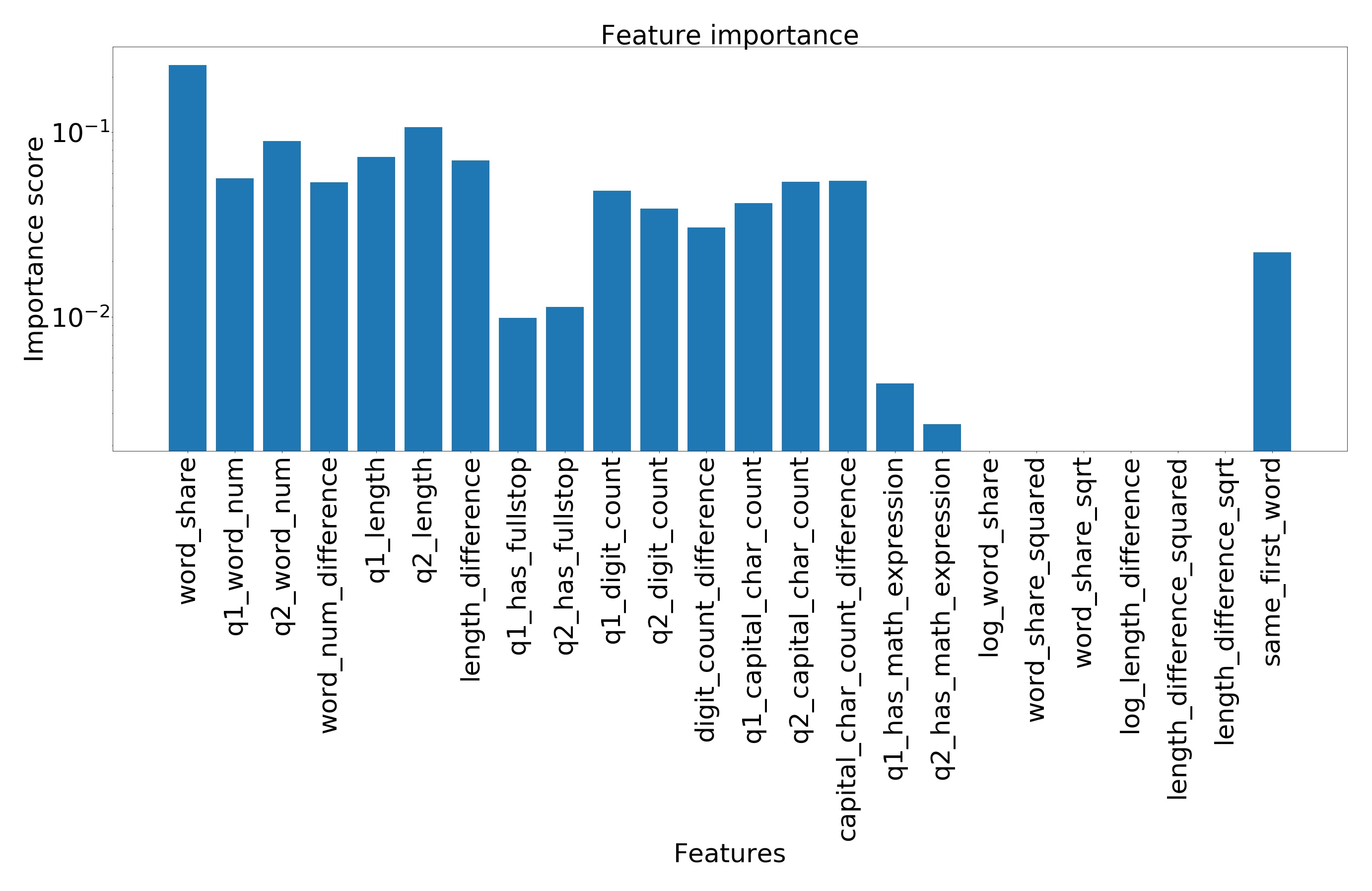
利用特征重要度实现降维,新修剪的特征包含所有重要度大于某个数字的特征。在我们的例子中,降维后的特征集合中,最小的重要度分数是0.05。
1 | def extract_pruned_features(feature_importances, min_score=0.05): |
基于特征重要度分析的模型性能
由于使用了修剪过的特征,随机森林模型的评估得分变得更高了,该算法不费吹灰之力将损失减小,而且由于特征集减少,训练速度更快,占用内存更少。
1 | model = RandomForestClassifier(50, n_jobs=8) |
深入考虑一下特征重要度评分(为修剪过的特征的某一子集绘制分类器的logloss),我们可以更大程度地降低损失。在这种特殊的情况下,随机森林实际上只使用一个特征就可以达到最佳效果!仅使用特征“word_share”就可以在logloss评估中获得0.5544的分数。
在《机器学习案例集》的代码中,你可以详细了解这个步骤是如何实现的。
结论
正如我所展示的,对特征重要度进行分析,能够提高模型的性能。虽然像XGBoost这样的一些模型为我们选择了特征,但是了解某个特征对模型性能的影响仍然很重要,因为它使我们能够更好地控制要完成的任务。“没有免费的午餐”定理(没有适合所有问题的最佳方案)告诉我们,尽管XGBoost通常比其他模型表现更好,但我们仍需要判断它是否真的是最佳解决方案。使用XGBoost获得重要特征的子集,允许我们在不选择特征的情况下,通过将该特征子集提供给模型来提高模型的性能。使用基于特征重要度的特征选择可以大大提高模型的性能。
原文链接:https://datawhatnow.com/feature-importance/
关注微信公众号:老齐教室。读深度文章,得精湛技艺,享绚丽人生。
若你觉得我的文章对你有帮助,欢迎点击上方按钮对我打赏

关注微信公众号,读文章、听课程,提升技能