让Python程序轻松加速的方法
2020-02-05
作者:Cameron MacLeod
翻译:老齐
最近,我读了一篇有趣的文章,文中介绍了一些未充分使用的Python特性的。在文章中,作者提到,从Python 3.2开始,标准库附带了一个内置的装饰器functools.lru_cache。我发现这个装饰器很令人兴奋,有了它,我们有可能轻松地为许多应用程序加速。
你可能在想,这很好,但这个装饰器究竟是什么?它提供对已构建的缓存的访问,该缓存使用LRU(译者注: Least Recently Used的缩写,即最近最少使用,是一种常用的页面置换算法,选择最近最久未使用的页面予以淘汰。)的置换策略,因此被命名为lru_cache。当然,这句话听起来可能有点令人胆怯,所以让我们把它分解一下。

什么是缓存?
缓存是一个可以快速访问的地方,可以在它里面存储访问速度较慢的内容。为了演示这一点,让我们以你的web浏览器为例。
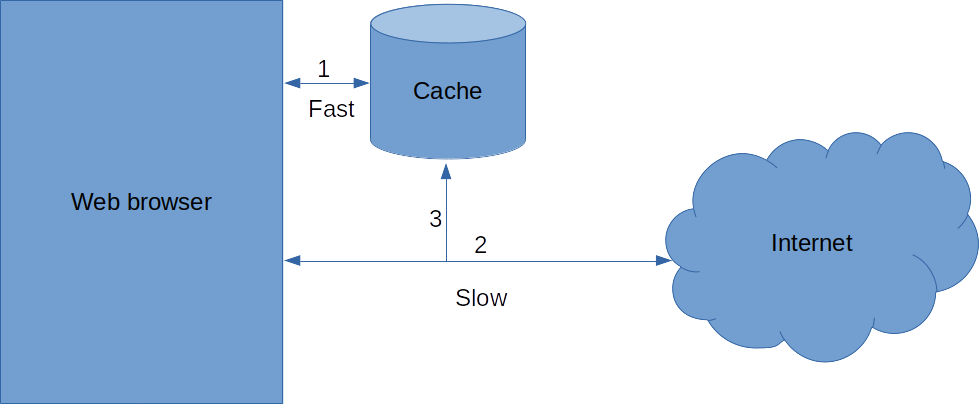
从网络上读取网页可能需要几秒钟,即使是快速的网络连接也如此。在计算机时代,这个问题是永恒的。为了解决这个问题,浏览器将你已经访问过的网页存储在计算机的缓存中,这样访问速度会加快数千倍。
使用缓存下载网页的步骤如下:
- 检查页面的本地缓存。如果页面在那里,返回该页面。
- 在因网上找到网页并从那里下载。
- 将该网页存储在缓存中,以便将来更快地访问。
虽然缓存并不会让你第一次访问网页的速度加快,但通常你是要屡次访问某一个网站页面的(想想Facebook——注:对多数国人来讲,可能不是这个网站,或者你的电子邮件),有了缓存之后,以后每次访问都会更快。
浏览器并不是唯一使用缓存的,从服务器到CPU和硬盘或SSD之间的计算机硬件,它们无处不在。从缓存中可以很快地获取数据,因此当你不止一次获取数据时,它可以大大加快程序的速度。
LRU是什么意思?
缓存只能存储有限数量的东西,而且通常它比可能存入所缓存的东西要小得多(例如,你的硬盘比互联网小得多)。这意味着有时需要将缓存中已有内容替换掉,放入其他内容。对于去掉什么的决策方法被称为置换策略。
这就是LRU的用武之地。LRU代表最近用得最少的缓存中内容,这是一种常用的缓存置换策略。
为什么置换策略很重要?
“最近使用最少”这种置换策略的基本思想是:如果你有一段时间没有访问过某个东西,你可能近期不会访问它。要使用此策略,只需在缓存已满时删除最早使用的项即可。

在上图中,缓存中的每个项都附带了访问时间。依据LRU策略,选择访问时间为2:55PM 的项作为要置换的项,因为它是最早被访问的。如果有两个对象具有相同的访问时间,那么LRU将从中随机选择一个。
这种去掉长时间不用的东西的策略,被称为Bélády的最优算法,它是置换缓存内容的最佳策略。当然,我们根本不知道未来会有什么操作。谢天谢地,在许多情况下,LRU提供了近乎最佳的性能。

怎样使用它?
functools.lru_cache是一个装饰器,因此你可以将它放在函数的顶部:
1 | import functools |
Fibonacci数列在递归示例中经常被用到,要提升这个函数的速度,使用functools.lru_cache之后,不费吹灰之力,就能让这个递归函数狂飙。在我的机器上运行这些代码,得到了这个函数有缓存版本和没有缓存版本的以下结果。
1 | $ python3 -m timeit -s 'from fib_test import fib' 'fib(30)' |
增加一行代码之后,速度提高了3565107倍。
当然,我认为很难看出你在实际中会如何使用它,因为我们很少需要计算斐波那契数列。回到web页面示例,我们可以举一个更实际的用缓存渲染前端模板的例子。
在服务器开发中,通常单个页面存储为具有占位符变量的模板。例如,下面是一个页面模板,该页面显示某一天各种足球比赛的结果。
1 | <html> |
呈现模板时,看起来如下所示:

这是缓存的主要目标,因为每天的结果不会改变,而且很可能每天会有多次访问。下面是一个提供此模板的Flask应用程序。我引入了50ms的延迟来模拟通过网络或者从大型数据库获取匹配字典。
1 | import json |
使用requests在不缓存的情况下获得三天的数据,在我的计算机上本地运行平均需要171ms。这还不错,但我们可以做得更好,即使考虑到人为的延迟。
1 | @app.route('/matches/<day>') |
在本例中,我设置了maxsize=4,因为我的测试脚本只有相同的三天,最好设置2次幂。使用这种方法,10个循环的平均速度可以降到13.7ms。

还有什么应该知道?
Python文档虽然很详细,但是有一些东西还是要强调的。
内置函数
装饰器附带了一些很有用的内置函数。cache_info()返回访问数(hits)、未访问数(misses)和当前缓存使用量(currsize)、最大容量(maxsize),帮助你了解缓存使用情况。cache_clear()将删除缓存中的所有元素。
有时候不要使用缓存
通常,只有在以下情况下才能使用缓存:
- 在缓存期内,数据不会更改。
- 函数将始终为相同的参数返回相同的值(因此时间和随机对缓存没有意义)。
- 函数没有副作用。如果缓存被访问,则永远不会调用该函数,因此请确保不更改其中的任何状态。
- 函数不返回不同的可变对象。例如,返回列表的函数不适合缓存,因为将要缓存的是对列表的引用,而不是列表内容。
原文链接:https://www.cameronmacleod.com/blog/python-lru-cache
关注微信公众号:老齐教室。读深度文章,得精湛技艺,享绚丽人生。
若你觉得我的文章对你有帮助,欢迎点击上方按钮对我打赏

关注微信公众号,读文章、听课程,提升技能