线程:概念和实现(2)
2020-02-16
翻译:老齐
译者注:与本文相关图书推荐:《Python大学实用教程》《跟老齐学Python:轻松入门》


第二部分
竞态条件
在讨论Python线程的其他特性之前,让我们先讨论一下编写线程程序时遇到的一个更困难的问题:竞态条件。
一旦你了解了什么是竞态条件,并看到了正在发生的情况,然后就使用标准库提供的模块,以防止这些竞态条件的出现。
当两个或多个线程访问共享数据或资源时,可能会出现竞态情况。在本例中,你将创建一个每次都发生的大型竞态条件,但请注意,大多数它并不是很明显。示例中的情况通常很少发生,而且会产生令人困惑的结果。可以想象,因为竞态条件而引起的bug很难被发现。
幸运的是,在下述示例中竞态问题每次都会发生,你将详细地了解它以便解释发生了什么。
对于本例,将编写一个更新数据库的类。你不会真的有一个数据库:你只是要伪造它,因为这不是本文的重点。
FakeDatabase类中有.__init__() 和 .update()方法:
1 | class FakeDatabase: |
FakeDatabase中的属性.value,用于作为竞态条件中共享的数据。
.__init__()中将.value值初始化为0.,到目前为止,一切正常。
.update() 看起来有点奇怪,它模拟从数据库中读取一个值,对其进行一些计算,然后将一个新值写回数据库。
所谓从数据库中读取,即将.value的值复制到本地变量。计算就是在原值上加1,然后.sleep() 一小会儿。最后,它通过将本地值复制回.value,将值写回去。
下面是FakeDatabase的使用方法:
1 | if __name__ == "__main__": |
程序中创建了两个ThreadPoolExecutor,然后对每个线程调用.submit(),告诉它们运行database.update()。
.submit()有一个明显特征,它允许将位置参数和命名参数传给线程中运行的函数:
1 | .submit(function, *args, **kwargs) |
在上面的用法中,index作为第一个也是唯一一个位置参数传给database.update()。你将在本文后面看到,可以用类似的方式传多个参数。
由于每个线程都运行.update(),而.update()会让.value的值加1,因此在最后打印时,你可能会希望database.value为2。但如果是这样的话,你就不会看这个例子了。如果运行上述代码,则输出如下:
1 | $ ./racecond.py |
你可能已经预料到这种情况会发生,但是让我们来看看实际情况的细节,因为这将使这个问题的解决方案更容易理解。
单线程
在用两个线程深入讨论这个问题之前,让我们先退一步,谈谈线程工作流程的一些细节。
我们不会在这里深入讨论所有的细节,因为这种全面深入的讨论现在并不重要。我们还将简化一些事情,这种做法虽然在技术上并不准确,但会让你对正在发生的事情有正确的认识。
当你告诉ThreadPoolExecutor运行每个线程时,也就是告诉它要运行哪个函数以及要传给它的参数:executor.submit(database.update, index)。
其结果是线程池中的每个线程都将调用database.update(index)。注意,database是__main__中创建的FakeDatabase实例对象,调用它的方法.update()。
每个线程都将引用同一个FakeDatabase的实例database,每个线程还将有一个唯一的值index。为了让上述过程更容易理解,请看下图:
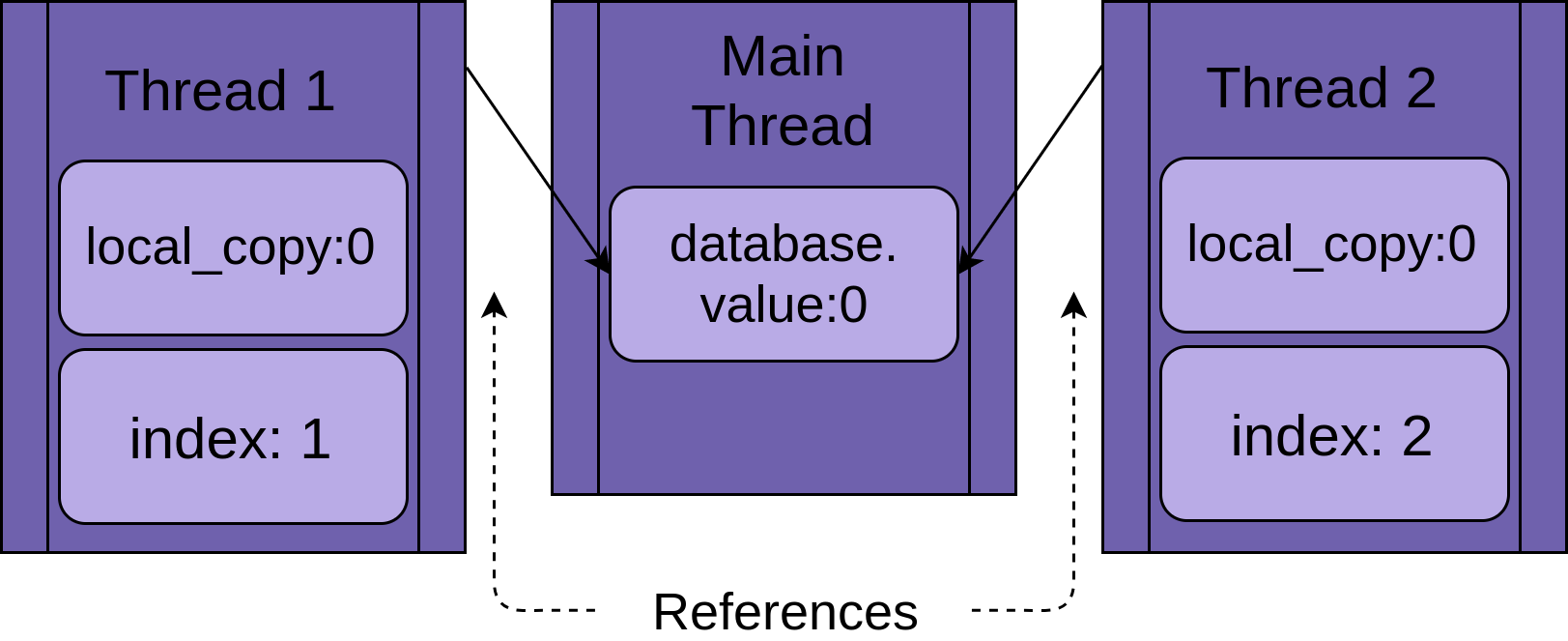
当某线程开始运行.update()时,它有此方法的本地的数据,即.update()中的local_copy。这绝对是件好事,否则,在两个线程中运行同一个函数就会互相干扰了。这意味着该函数的所有作用域(或本地)变量对于线程来说都是安全的。
现在,你已经理解,如果使用单个线程和对.update()的单个调用来运行上面的程序会发生什么情况。
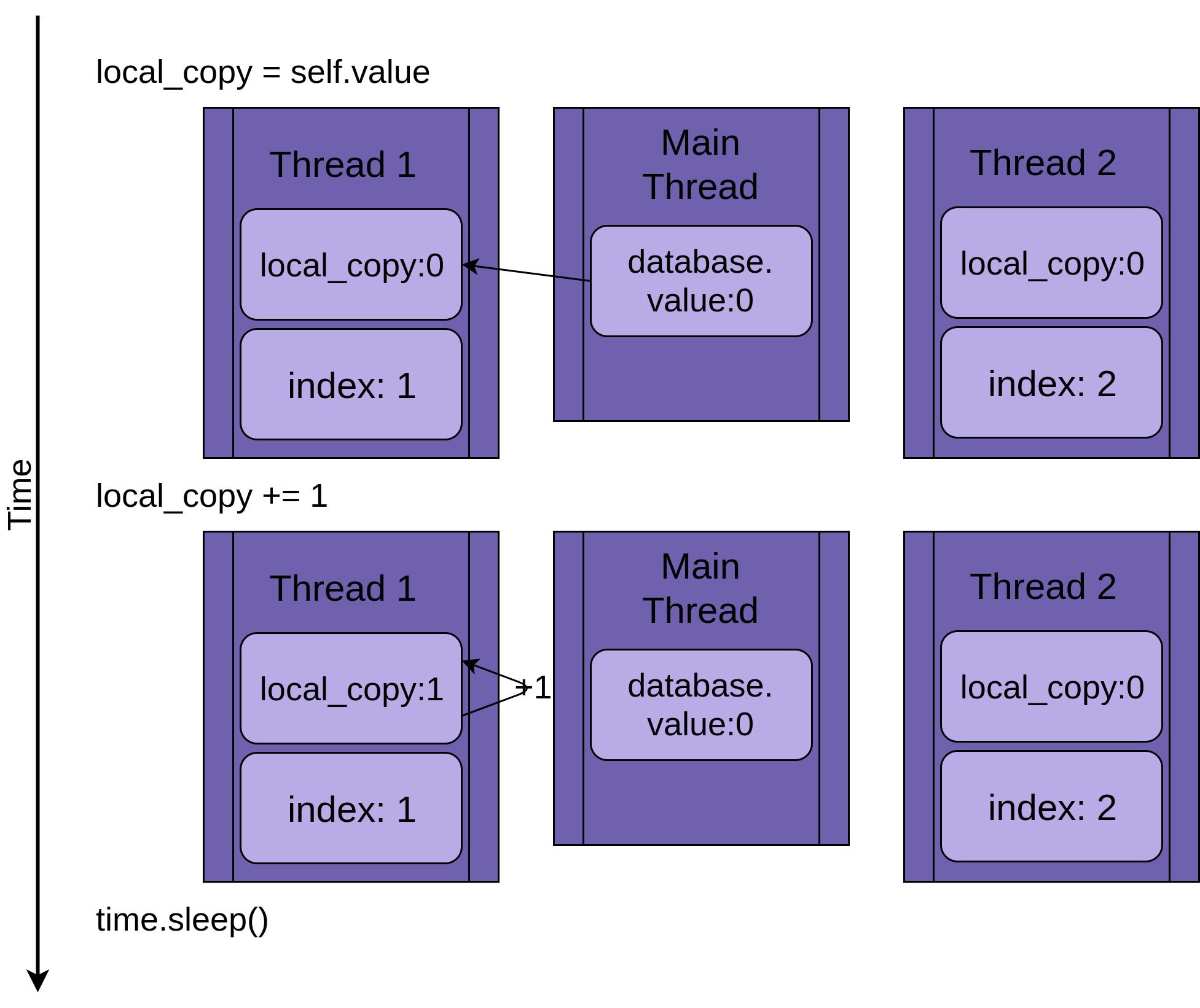
如果只运行一个线程,如下图所示,会一步一步地执行.update()。下图中,语句显示在上面,下面用图示方式演示了线程中的local_value和共享的database.value 中的值的变化:

按照时间顺序,从上到下观察上面的示意图,从创建线程Thread 1开始,到Thread 1结束终止。
Thread 1启动时,FakeDatabase.value为零。方法中的第一行代码local_copy=self.value将0复制到局部变量。接下来,使用local_copy+=1语句增加local_copy的值。你可以看到Thread 1中的.value值为1。
然后,调用下一个time.sleep(),这将使当前线程暂停并允许其他线程运行。因为在这个例子中只有一个线程,所以这没有影响。
当Thread 1唤醒并继续时,它将新值从local_copy复制到FakeDatabase.value,然后线程完成。你可以看到database.value为1。
到目前为止,一切正常。你只运行了一次.update()并且将FakeDatabase.value递增为1。
两个线程
回到竞态条件,两个线程并行,但不是同时运行。每个线程都有自己的local_copy,并指向相同的database,正是这个共享数据库对象导致了这些问题。
程序还是从Thread 1执行.update()开始:
当Thread 1调用time.sleep()时,它允许另一个线程开始运行。这就是事情变得有趣的地方。
Thread 2启动并执行相同的操作。它也将database.value复制到其私有的local_copy,而此时共享的database.value尚未更新:
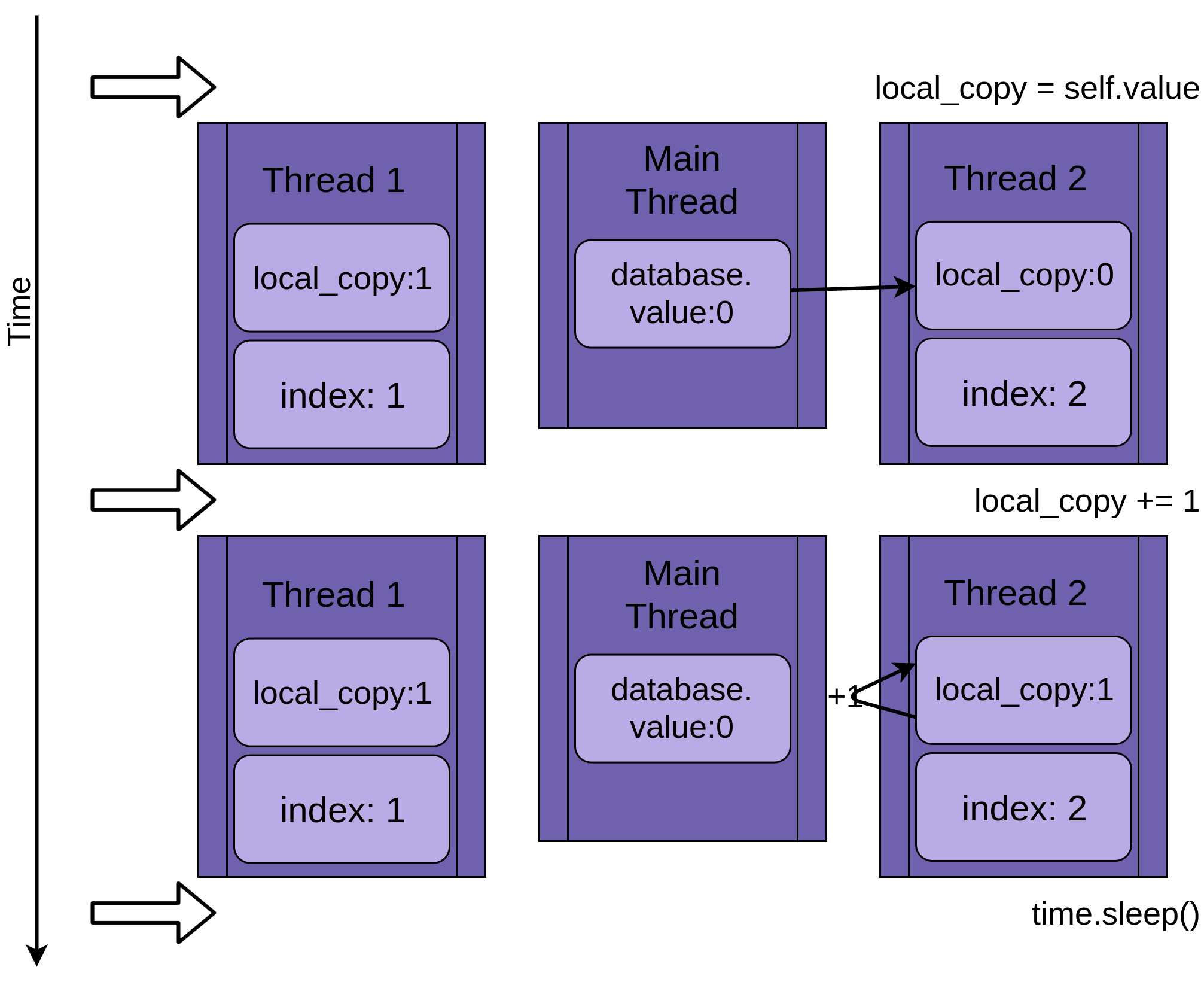
当Thread 1进入睡眠状态时,共享的database.value仍然未被修改,还是0,而此时的local_copy的两个私有版本的值都为1。
Thread 1现在醒来并保存其local_copy的值,然后线程终止,给Thread 2机会。Thread 2不知道在它睡眠时Thread 1运行并更新了database.value的值。Thread 2也将它的local_copy值存储到database.value中,并将其设置为1:

这两个线程交替访问一个共享对象,覆盖彼此的结果。当一个线程释放内存或在另一个线程完成访问之前关闭文件句柄时,可能会出现类似的竞态。
为什么这不是一个愚蠢的示例
上面的例子是刻意而为,目的是确保每次运行程序时都会发生竞态。因为操作系统可以在任何时候交换线程,所以在读取x的值之后,并且在写回递增的值之前,可以中断类似x=x+1的语句。
发生这种情况的原因细节非常有趣,但这篇文章的其余部分并不需要这些细节,所以可以跳过这个隐藏的部分。
既然你已经看到了运行过程中的竞态条件,让我们找出解决问题的方法!
使用锁实现同步
有很多方法可以避免或解决竞态。你不会在这里看到所有这些方法,但是有一些方法是经常使用的。让我们从Lock开始。
要解决上述竞态条件,需要找到一种方法,使得在代码的“读-修改-写”操作中一次只允许一个线程。最常见的方法是使用Python中名为Lock的方法。在其他的一些语言中,类似的被称为Mutex,Mutex源于MUTual EXclusion,这正是Lock的作用。
Lock像是通行证,一次只能有一个线程拥有Lock,任何其他想要Lock的线程都必须等到Lock的所有者放弃它。
执行此操作的基本函数是.acquire() 和 .release()。线程将调用my_lock.acquire()来获取自己的锁。如果锁已经被其他线程所有,则将等待它被释放。这里有一点很重要,如果一个线程得到了锁,但尚未返回,你的程序将被卡住。你稍后会读到更多关于这方面的内容。
幸运的是,Python的Lock也将作为上下文管理器运行,因此你可以在一个带有with的语句中使用它,并且当with代码块由于任何原因退出时,锁也会自动释放。
让我们看看添加了锁的FakeDatabase,其所调用函数保持不变:
1 | class FakeDatabase: |
除了添加一堆调试日志以便更清楚地看到锁操作之外,这里的大变化是添加一个名为._lock的属性,它是一个threading.Lock()实例对象。这个._lock在未锁定状态下初始化,并由with语句锁定和释放。
这里值得注意的是,运行此方法的线程将一直保持Lock,直到完全完成对数据库的更新。在这种情况下,这意味着函数将在复制、更新、休眠时保持锁定,然后将值写回数据库。
如果在日志记录设置为警告级别的情况下运行此版本,你将看到以下内容:
1 | $ ./fixrace.py |
看看这个。你的程序终于成功了!
在__main__中配置日志输出后,可以通过添加以下语句将级别设置为DEBUG来打开完整日志记录:
1 | logging.getLogger().setLevel(logging.DEBUG) |
在启用DEBUG后,运行此程序,如下所示:
1 | $ ./fixrace.py |
在输出中,你可以看到Thread 0得到了锁,并在进入睡眠状态时仍保持锁定。然后Thread 1启动并尝试获取相同的锁。因为Thread 0仍在持有锁,Thread 1必须等待。这就是Lock的互斥性。
本文其余部分中的许多示例将日志设置为WARNING和DEBUG级别。我们通常只是DEBUG级别的输出,因为DEBUG日志可能非常长。在日志记录打开的情况下尝试这些程序,看看它们能做什么。
死锁
在继续探索之前,应该先看看使用锁时的一个常见问题。如你所见,如果已经获取了Lock,则对.acquire()的二次调用将等到持有Lock的线程调用.release()。运行此代码时,你认为会发生什么情况?
1 | import threading |
当程序第二次调用l.acquire()时,该函数将挂起,等待Lock的释放。在本例中,可以通过删除第二次调用来修复死锁,但死锁通常发生在以下两个微妙的事情之一:
- 未正确释放
Lock的错误。 - 设计问题,其中一个函数需要由某些函数调用,这些函数可能具有或可能不具有
Lock。
第一种情况有时会发生,但使用Lock作为上下文管理器会大大减少错误出现的频率。建议尽可能使用上下文管理器编写代码,因为它们有助于避免异常跳过.release()调用的情况。
在某些语言中,设计问题可能要复杂一些。值得庆幸的是,Python线程的又一个对象RLock就是为这种情况而设计的。它允许线程在调用.release()之前多次通过.acquire()实现RLock。该线程中调用.release()的次数与调用.acquire()的次数相同。
Lock和RLock是线程中用来防止竞态条件的两个基本工具,还有一些其他工具以不同的方式发挥作用。在你查看它们之前,让我们转到一个稍微不同的问题上。
(未完待续)
原文链接:https://realpython.com/intro-to-python-threading/
关注微信公众号:老齐教室。读深度文章,得精湛技艺,享绚丽人生。
若你觉得我的文章对你有帮助,欢迎点击上方按钮对我打赏

关注微信公众号,读文章、听课程,提升技能