如何合并没有共同标识符的数据集
2020-03-13
作者: Chris Moffitt
翻译:老齐
与本文相关的图书推荐:《数据准备和特征工程》

引言
合并数据集,是数据科学中常见的操作。对于有共同标识符的两个数据集,可以使用Pandas中提供的常规方法合并,但是,如果两个数据集没有共同的唯一标识符,怎么合并?这就是本文所要阐述的问题。对此,有两个术语会经常用到:记录连接和模糊匹配,例如,尝试把基于人名把不同数据文件连接在一起,或合并只有组织名称和地址的数据等,都是利用“记录链接”和“模糊匹配”完成的。
合并没有共同特征的数据,是比较常见且具有挑战性的业务,很难系统地解决,特别是当数据集很大时。如果用人工的方式,使用Excel和查询语句等简单方法能够实现,但这无疑要有很大的工作量。如何解决?Python此时必须登场。Python中有两个库,它们能轻而易举地解决这种问题,并且可以用相对简单的API支持复杂的匹配算法。
第一个库叫做fuzzymatcher,它用一个简单的接口就能根据两个DataFrame中记录的概率把它们连接起来,第二个库叫做RecordLinkage 工具包,它提供了一组强大的工具,能够实现自动连接记录和消除重复的数据。
在本文中,我们将学习如何使用这两个工具(或者两个库)来匹配两个不同的数据集,也就是基于名称和地址信息的数据集。此外,我们还将简要学习如何把这些匹配技术用于删除重复的数据。
问题
只要试图将不同的数据集合并在一起,任何人都可能遇到类似的挑战。在下面的简单示例中,系统中有一个客户记录,我们需要确定数据匹配,而又不使用公共标识符。(下图中箭头标识的两个记录,就是要匹配的对象,它们没有公共标识符。)

根据一个小样本的数据集和我们的直觉,记录号为18763和记录号为A1278两条记录看起来是一样的。我们知道Brothers 和 Bro以及Lane和LN是等价的,所以这个过程对人来说相对容易。然而,尝试在编程中利用逻辑来处理这个问题就是一个挑战。
以我的经验,大多数人会想到使用Excel,查看地址的各个组成部分,并根据州、街道号或邮政编码找到最佳匹配。在某些情况下,这是可行的。但是,我们可能希望使用更精细的方法来比较字符串,为此,几年前我曾写过一个叫做fuzzywuzzy的包。
挑战在于,这些算法(例如Levenshtein、Damerau-Levenshtein、Jaro-Winkler、q-gram、cosine)是计算密集型的,在大型数据集上进行大量匹配是无法调节比例的。
如果你有兴趣了解这些概念上的更多数学细节,可以查看维基百科中的有关内容,本文也包含了一些详解。最后,本文将更详细地讨论字符串匹配的方法。
幸运的是,有一些Python工具可以帮助我们实现这些方法,并解决其中的一些具有挑战性的问题。
数据
在本文中,我们将使用美国医院的数据。之所以选这个数据集,是因为医院的数据具有一些独特性,使其难以匹配:
- 许多医院在不同的城市都有相似的名字(圣卢克斯、圣玛丽、社区医院,这很类似我国很多城市都有“协和医院”一样)
- 在某个城市内,医院可以占用几个街区,因此地址可能不明确
- 医院附近往往有许多诊所和其他相关设施
- 医院也会被收购,名字的变更也很常见,从而使得数据处理过程更加困难
- 最后,美国有成千上万的医疗机构,所以这个问题很难按比例处理
在这些例子中,我有两个数据集。第一个是内部数据集,包含基本的医院帐号、名称和所有权信息。

第二个数据集包含医院信息(含有Provider的特征),以及特定心衰手术的出院人数和医疗保险费用。
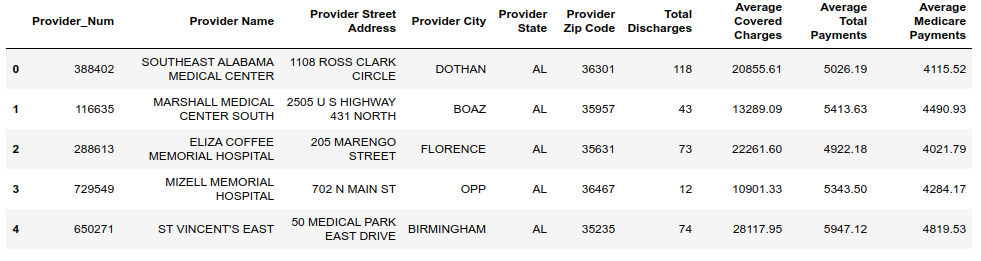
以上数据集来自Medicare.gov 和 CMS.gov,并经过简单的数据清洗。
本文项目已经发布到在线实验平台,请关注微信公众号《老齐教室》后,回复:#姓名+手机号+案例#。注意,#符号不要丢掉,否则无法查找到回复信息。

我们的业务场景:现在有医院报销数据和内部帐户数据,要讲两者进行匹配,以便从更多层面来分析每个医院的患者。在本例中,我们有5339个医院帐户和2697家医院的报销信息。但是,这两类数据集没有通用的ID,所以我们将看看是否可以使用前面提到的工具,根据医院的名称和地址信息将两个数据集合并。
方法1:fuzzymather包
在第一种方法中,我们将尝试使用fuzzymatcher,这个包利用sqlite的全文搜索功能来尝试匹配两个不同DataFrame中的记录。
安装fuzzymatcher很简单,如果使用conda安装,依赖项会自动检测安装,也可以使用pip安装fuzzymatcher。考虑到这些算法的计算负担,你会希望尽可能多地使用编译后的c组件,可以用conda实现。
在所有设置完成后,我们导入数据并将其放入DataFrames:
1 | import pandas as pd |
以下是医院账户信息:

Here is the reimbursement information:
这是报销信息:
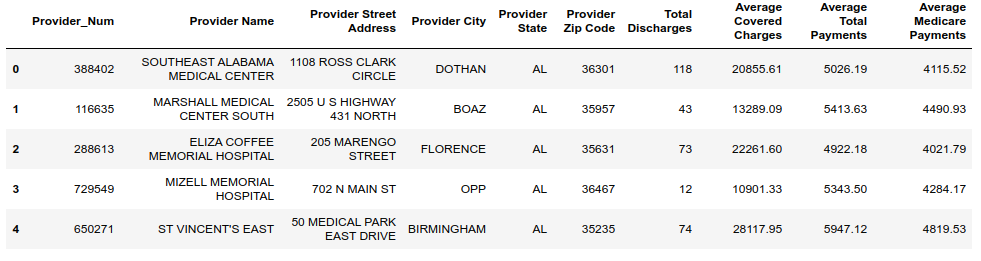
由于这些列有不同的名称,我们需要定义哪些列与左右两边的DataFrame相匹配,医院帐户信息是左边的DataFrame,报销信息是右边的DataFrame。
1 | left_on = ["Facility Name", "Address", "City", "State"] |
现在用fuzzymatcher中的fuzzy_left_join函数找出匹配项:
1 | matched_results = fuzzymatcher.fuzzy_left_join(hospital_accounts, |
在幕后,fuzzymatcher为每个组合确定最佳匹配。对于这个数据集,我们分析了超过1400万个组合。在我的笔记本电脑上,这个过程花费了2分11秒。
变量matched_results所引用的DataFrame对象包含连接在一起的所有数据以及best_match_score——这个特征的数据用于评估该匹配连接的优劣。
下面是这些列的一个子集,前5个最佳匹配项经过重新排列增强了可读性:
1 | cols = [ |

第一个项目的匹配得分是3.09分,看起来肯定是良好的匹配。你可以看到,对位于Red Wing的Mayo诊所,特征Facility Name和Provider Name的值基本一样,观察结果也证实这条匹配是很合适的。
我们也可以查看哪些地方的匹配效果不好:
1 | matched_results[cols].sort_values(by=['best_match_score'], ascending=True).head(5) |
这里显示了一些糟糕的分数以及明显的不匹配情况:

这个例子凸显了一部分问题,即一个数据集包括来自Puerto Rico的数据,而另一个数据集中没有,这种差异明确显示,在尝试匹配之前,你需要确保对数据的真正了解,以及尽可能对数据进行清理和筛选。
我们已经看到了一些极端的情况。现在看一看,分数小于0.8的一些匹配,它们可能会更具挑战性:
1 | matched_results[cols].query("best_match_score <= .80").sort_values( |

上述示例展示了一些匹配如何变得更加模糊,例如,ADVENTIST HEALTH UKIAH VALLEY)是否与UKIAH VALLEY MEDICAL CENTER 相同?根据你的数据集和需求,你需要找到自动和手动匹配检查的正确平衡点。
总的来说,fuzzymatcher是一个对中型数据集有用的工具。如果样本量超过10000行时,将需要较长时间进行计算,对此,要有良好的规划。然而,fuzzymatcher的确很好用,特别是与Pandas结合,使它成为一个很好的工具。
方法2:RecordLinkage工具包
RecordLinkage工具包提供了另一组强有力的工具,用于连接数据集中的记录和识别数据中的重复记录。
其主要功能如下:
- 能够根据列的数据类型,为每个列定义匹配的类型
- 使用“块”限制潜在的匹配项的池
- 使用评分算法提供匹配项的排名
- 衡量字符串相似度的多种算法
- 有监督和无监督的学习方法
- 多种数据清理方法
权衡之下,如果仅仅是为了进一步验证而管理这些数据结果,这些操作就有点太复杂了。然而,这些步骤都会用标准的Panda指令实现,所以不要害怕。
依然可以使用pip来安装库。我们将使用前面的数据集,但会在读取数据的时候设置某列为索引,这使得后续的数据连接更容易解释。
1 | import pandas as pd |
因为RecordLinkage有更多的配置选项,所以我们需要几个步骤来定义连接规则。第一步是创建indexer对象:
1 | indexer = recordlinkage.Index() |
1 | # 输出 |
这个警告指出了记录连接库和模糊匹配器之间的区别。通过记录连接,我们可以灵活地影响评估的记录对的数量。调用索引对象的full方法,可以计算出所有可能的记录对(我们知道这些记录对的数量超过了14M)。我过一会儿再谈其他的选择,下面继续探讨完整的索引,看看它是如何运行的。
下一步是建立所有需要检查的潜在的候选记录:
1 | candidates = indexer.index(hospital_accounts, hospital_reimbursement) |
1 | # 输出 |
这个快速检查恰好确认了比较的记录总数。
既然我们已经定义了左、右数据集和所有候选数据集,就可以使用Compare()进行比较。
1 | compare = recordlinkage.Compare() |
以上选定几个特征,用它们确定一个城市的精确匹配,此外在执行string方法中还设置了阈值。除了这些选参数之外,你还可以定义其他一些参数,比如数字、日期和地理坐标。了解更多示例,请参阅文档。
最后一步是使用compute方法对所有特征进行比较。在本例中,我们使用完整索引,用时3分钟41秒。
下面是一个优化方案,这里有一个重要概念,就是块,使用块可以减少比较的记录数量。例如,如果只想比较处于同一个州的医院,我们可以依据State列创建块:
1 | indexer = recordlinkage.Index() |
1 | # 输出 |
依据State分块,候选项将被筛选为只包含州值相同的那些,筛选后只剩下475,830条记录。如果我们运行相同的比较代码,只需要7秒。一个很好的加速方法!
在这个数据集中,State的数据是干净的,但是如果有点混乱的话,还可以使用另一种分块算法,比如SortedNeighborhood,减少一些小的拼写错误带来的影响。
例如,如果州名包含“Tenessee”和“Tennessee”怎么办?前面的分块就无效了,但可以使用sortedneighbourhood方法处理此问题。
1 | indexer = recordlinkage.Index() |
1 | # 输出 |
上述示例,sortedneighbourhood处理了998,860个记录,花费了15.9秒,这一操作似乎很合理的。
不管你使用哪个方法,结果都入下所示,是一个DataFrame。
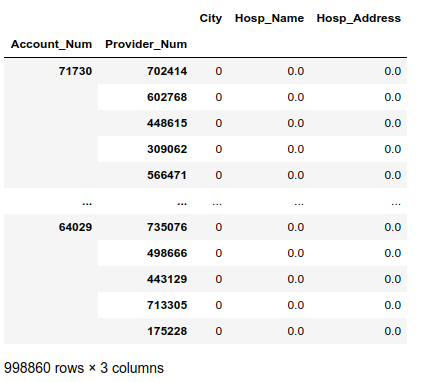
这个DataFrame显示所有比较的结果,在帐户和报销DataFrames中,每行有一个比较结果。这些项目对应着我们所定义的比较,1代表匹配,0代表不匹配。
由于大量记录没有匹配项,难以看出我们可能有多少匹配项,为此可以把单个的得分加起来查看匹配的效果。
1 | features.sum(axis=1).value_counts().sort_index(ascending=False) |
1 | # 输出 |
现在我们知道有988187行没有任何匹配值,7937行至少有一个匹配项,451行有2个匹配项,2285行有3个匹配项。
为了使剩下的分析更简单,让我们用2或3个匹配项获取所有记录,并添加总分:
1 | potential_matches = features[features.sum(axis=1) > 1].reset_index() |

下面是对所得结果进行解释:索引为1的行,Account_Num值为26270、Provider_Num值为868740,该行显示,在城市、医院名称和医院地址方面相匹配。
再详细查看这两个记录的内容:
1 | hospital_accounts.loc[26270,:] |
1 | Facility Name SCOTTSDALE OSBORN MEDICAL CENTER |
1 | hospital_reimbursement.loc[868740,:] |
1 | Provider Name SCOTTSDALE OSBORN MEDICAL CENTER |
是的。它们看起来很匹配。
现在我们知道了匹配项,还需要对数据进行调整,以便更容易地对所有数据进行检查。我将为每一个数据集创建一个用于连接的名称和地址查询。
1 | hospital_accounts['Acct_Name_Lookup'] = hospital_accounts[[ |
现在与帐户信息数据合并:
1 | account_merge = potential_matches.merge(account_lookup, how='left') |
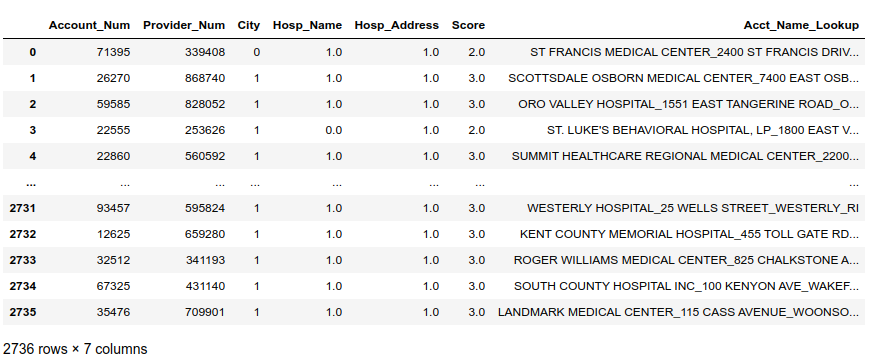
最后,与报销数据合并:
1 | final_merge = account_merge.merge(reimbursement_lookup, how='left') |
看看最终的数据:
1 | cols = ['Account_Num', 'Provider_Num', 'Score', |
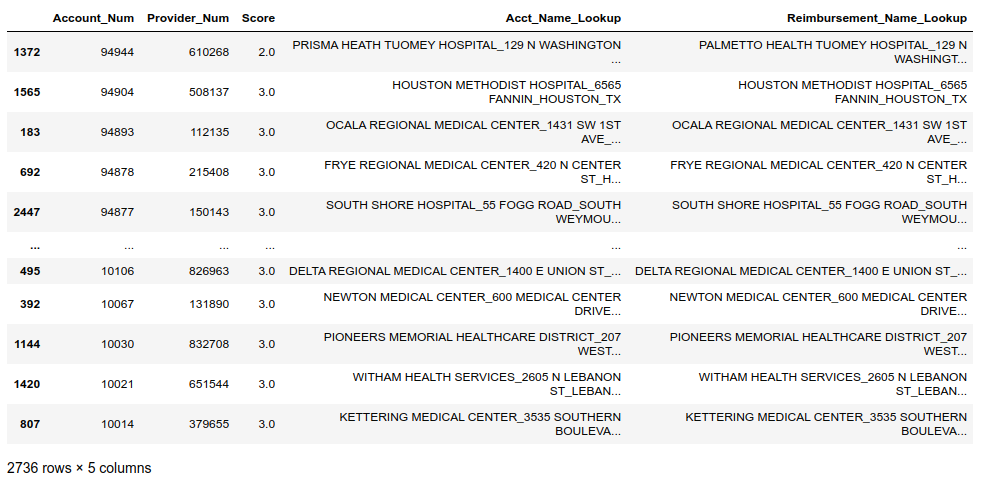
此处演示的方法和fuzzymatcher有所不同,fuzzymatcher往往包含多个匹配结果,例如,帐号32725可以匹配两个对应项:
1 | final_merge[final_merge['Account_Num']==32725][cols] |

在这种情况下,需要有人找出哪一个匹配是最好的。幸运的是,很容易将所有数据保存到Excel中并进行进一步分析:
1 | final_merge.sort_values(by=['Account_Num', 'Score'], |
从这个例子中可以看到,RecordLinkage工具包比fuzzymatcher更加灵活,便于自定义。RecordLinkage也并非完美,例如对个人而言,RecordLinkage需要执行更多操作步骤才能完成数据的比较。
删除重复数据
RecordLinkage的另一个用途是查找数据集里的重复记录,这个过程与匹配非常相似,只不过是你传递的是一个针对自身的DataFrame。
我们来看一个使用类似数据集的例子:
1 | hospital_dupes = pd.read_csv('hospital_account_dupes.csv', index_col='Account_Num') |
然后创建索引对象,并基于State执行sortedneighbourhood。
1 | dupe_indexer = recordlinkage.Index() |
根据城市、名称和地址检查是否有重复记录:
1 | compare_dupes = recordlinkage.Compare() |
因为只与单个DataFrame进行比较,因此得到的DataFrame带有Account_Num_1和Account_Num_2:
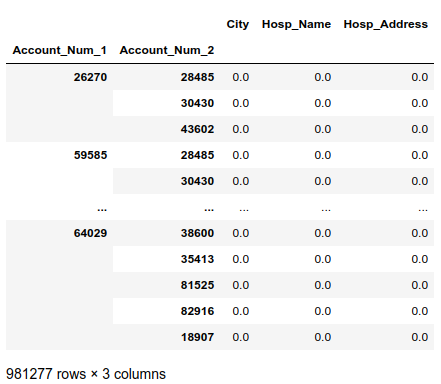
下面是我们的评分方法:
1 | dupe_features.sum(axis=1).value_counts().sort_index(ascending=False) |
1 | 3.0 7 |
添加分数列:
1 | potential_dupes = dupe_features[dupe_features.sum(axis=1) > 1].reset_index() |
下面是一个例子:
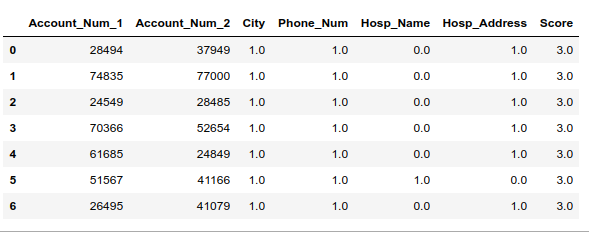
这些记录很有可能是重复的,我们来查看其中一组,看看他们是不是相同的记录:
1 | hospital_dupes.loc[51567, :] |
1 | Facility Name SAINT VINCENT HOSPITAL |
1 | hospital_dupes.loc[41166, :] |
1 | Facility Name ST VINCENT HOSPITAL |
没错,观察结果说明它们有可能是重复记录,姓名和地址相似,电话号码只少了一位数字。
如你所见,这种是一个强大且相对容易的工具,用于检查数据和重复的记录。
高级用法
除了这里展示的匹配方法之外,RecordLinkage还包含了用于匹配记录的几种机器学习方法。我鼓励感兴趣的读者阅读文档中的示例。
其中一个非常方便的功能是:有一个基于浏览器的工具,它可以用来为机器学习算法生成记录对。
本文所介绍的两个包,都包含一些预处理数据的功能,以便使匹配更加可靠。
总结
在数据处理上,经常会遇到诸如“名称”和“地址”等文本字段连接不同的记录的问题,这是很有挑战性的。Python生态系统包含两个有用的库,它们可以使用多种算法将多个数据集的记录进行匹配。
fuzzymatcher对全文搜索,通过概率实现记录连接,将两个DataFrames简单地匹配在一起。如果你有更大的数据集或需要使用更复杂的匹配逻辑,那么RecordLinkage是一组非常强大的工具,用于连接数据和删除重复项。
原文链接:https://pbpython.com/record-linking.html
搜索技术问答的公众号:老齐教室
为了方便大家阅读、查询本微信公众号的资源,回复:老齐,即可显示本公众号的服务目录。
若你觉得我的文章对你有帮助,欢迎点击上方按钮对我打赏

关注微信公众号,读文章、听课程,提升技能