写给初学者的LASSO回归
2020-03-20
作者:Benjamin Obi Tayo Ph.D.
翻译:老齐
与本文相关的图书:《数据准备和特征工程》


LASSO回归是对回归算法正则化的一个例子。正则化是一种方法,它通过增加额外参数来解决过拟合问题,从而减少模型的参数、限制复杂度。正则化线性回归最常用的三种方法是岭回归、最小绝对值收敛和选择算子(LASSO)以及弹性网络回归。
在本文中,我将重点介绍LASSO,并且对岭回归和弹性网络回归做简单的扩展。
假设我们想在一个数据集上建立一个正则化回归模型,这个数据集包含n个观察和m个特征。
LASSO回归是一个L1惩罚模型,我们只需将L1范数添加到最小二乘的代价函数中:

看这里

通过增大超参数α的值,我们加强了模型的正则化强度,并降低了模型的权重。请注意,没有把截距项w0正则化,还要注意α=0对应于标准回归。
通过调整正则化的强度,某些权重可以变为零,这使得LASSO方法成为一种非常强大的降维技巧。
LASSO算法
- 对于给定的α,只需把代价函数最小化,即可找到权重或模型参数w。
- 然后使用下面的等式计算w(不包括w0)的范数:
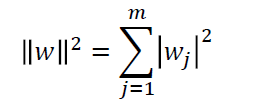
案例研究:使用游轮数据集预测船员人数
我们将使用邮轮数据集cruise_ship_info.csv来演示LASSO技术
本案例已经发布在实验平台,请关注微信公众号:老齐教室。并回复:
#姓名+手机号+案例#获取。注意:#必须要有。
1.导入必要的库
1 | import numpy as np |
2.读取数据集并显示列
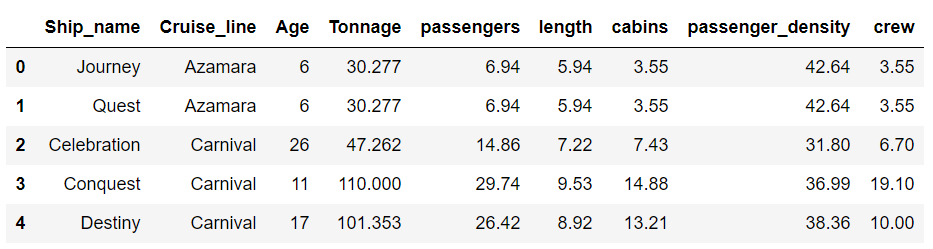
1 | df = pd.read_csv("cruise_ship_info.csv") |
3.选择重要的变量
从《数据准备和特征工程》中的有关阐述可知,协方差矩阵图可用于特征选择和降维。从前述数据集中发现,在6个预测特征( [‘age’, ‘tonnage’, ‘passengers’, ‘length’, ‘cabins’, ‘passenger_density’])中,如果我们假设重要特征与目标变量的相关系数为0.6或更大,那么目标变量“crew”与4个预测变量“tonnage”, “passengers”, “length, and “cabins”的相关性很强。因此,我们能够将特征空间的维数从6减少到4。
1 | cols_selected = ['Tonnage', 'passengers', 'length', 'cabins','crew'] |
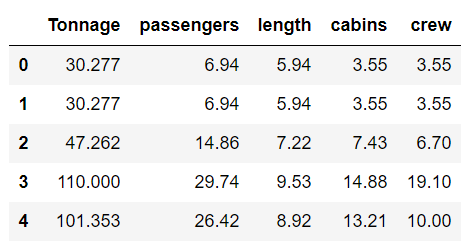
1 | X = df[cols_selected].iloc[:,0:4].values # features matrix |
4. 实现LASSO回归
a.将数据集分成训练集和测试集
1 | from sklearn.model_selection import train_test_split |
b.特征数据区间化
1 | from sklearn.preprocessing import StandardScaler |
c.实现LASSO回归
1 | from sklearn.linear_model import Lasso |
d.可视化结果
1 | plt.figure(figsize=(8,6)) |
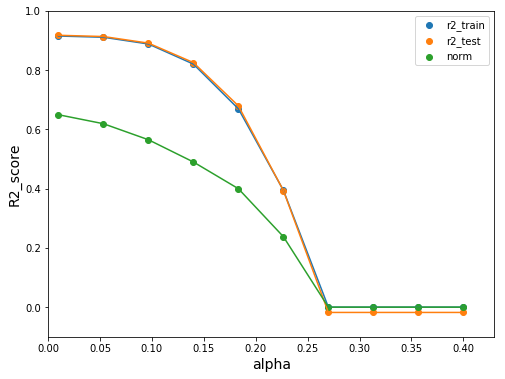
我们观察到,随着正则化参数α的增加,回归系数的范数变得越来越小。这意味着更多的回归系数被强制为零,这会增加偏差(模型过度简化)。α保持较低值时,比如α=0.1或更低时,是偏差和方差的最佳平衡点。在决定使用哪种降维方法之前,应将该方法与主成分分析法(PCA)进行比较。
原文链接:https://towardsdatascience.com/lasso-regression-tutorial-fd68de0aa2a2
搜索技术问答的公众号:老齐教室
在公众号中回复:老齐,可查看所有文章、书籍、课程。
若你觉得我的文章对你有帮助,欢迎点击上方按钮对我打赏

关注微信公众号,读文章、听课程,提升技能