写给小白:K近邻算法入门
2020-03-30
作者:Philipp Muens
翻译:老齐
与本文相关的图书推荐:《数据准备和特征工程》(电子工业出版社天猫旗舰店有售)

本文的代码,均发布到百度AI Studio的在线平台中,关注微信公众号「老齐教室」,并回复:#真实姓名+手机号+‘案例’#,申请加入含有苯问案例的《机器学习案例》课程,得到包含本案例在内的更多机器学习案例。注意: 回复信息中(1)必须以#开始和结尾(2)必须是真实姓名和手机号。
K近邻(简称K-NN或KNN)是一种简单而优雅的机器学习算法,用于根据现有数据对不可见的数据进行分类。该算法的优点是不需要传统的训练阶段。如果存在分类问题和标记数据,则可以利用现有的已分类数据,预测任何不可见的数据类别。
让我们仔细看看核心思想背后相关的数学知识和将这些转化为代码的过程。
原理
想象一下,我们邀请了100个养狗的人带着他们的狗过来做一个我们想做的统计实验。每只参与实验的狗是我们感兴趣的4个不同犬种中的1个。在这些狗及其主人的配合下,我们测量每只狗的3种不同属性:
- weight: 重量(千克)
- height: 高度(厘米)
- alertness: 警觉性(从0到1[1=非常警觉,0=几乎没有警觉])
测量完成后,我们将测量值标准化,使其在000到111之间。
在收集了每只狗的数据后,我们得到了100个测量值,每个测量值都标有相应的狗品种。
下面是一个例子:
$$\begin{bmatrix}0.5\0.8\0.1\end{bmatrix}=Podenco$$
为了更好地理解数据,最好把它标出来。由于我们收集了3种不同的测量数据(重量、高度和警惕性),因此可以将所有100个数据点投影到三维空间中,并根据其标签为每个数据点上色(例如,把“Podenco”的标签涂上棕色)。
不幸的是,我们在试图绘制此数据时遇到问题,因为我们忘了标注其中的一个测量数据。我们确实有狗的重量,高度和警觉性,但由于某种原因,我们忘记写下这只狗的品种。
既然我们已经有其他狗的测量数据,有没有可能推测出这只狗的品种呢?我们仍然可以将未标记的数据添加到现有三维空间中,所有其他的彩色数据点都在这个空间里。但我们该怎么给这个推测的数据点上色呢?
一个可能的解决方案是查看问题数据点周围的5个邻居,看看它们是什么颜色的。如果这些数据点中的大多数标记为“Podenco”,那么我们的测量数据很可能也是从Podenco中获取的。
这正是K-NN算法(k近邻算法)的作用。该算法根据一个不可见数据点的K近邻和这些K近邻的绝大多数类型,来预测该数据点的类。让我们从数学的角度来仔细研究一下这个问题。
两个概念
为了通过K-NN对数据进行分类,我们只需要实现两个概念。
如上所述,该算法通过查看K个最近邻和它们各自的大多数类来对数据进行分类。
因此我们需要实现两个函数:距离函数和投票函数。前者用于计算两点之间距离的,后者返回给定的任意标签列表中最常见的标签。
距离函数
考虑到“最近邻”的概念,我们需要计算“待分类”数据点与所有其他数据点之间的距离,以找到距离最近的点。
有几个不同的距离函数。对于我们的实现,将使用欧几里德距离,因为它计算简单,可以很容易地扩展到多维。
用数学符号表示如下:
$$d(x, y)=d(y, x)=\sqrt{\sum_{i=1}^N(x_i-y_i)^2}$$
让我们通过一个例子来解释这个公式。假设有两个向量$\overrightarrow{a}$和$\overrightarrow{b}$,两者之间的欧氏距离计算如下:
$$\overrightarrow{a}=\begin{pmatrix}1\2\3\4\end{pmatrix} \overrightarrow{b}=\begin{pmatrix}5\6\7\8\end{pmatrix}$$
$$d(\overrightarrow{a},\overrightarrow{b})=d(\overrightarrow{b},\overrightarrow{a})=\sqrt{(1-5)^2+(2-6)^2+(3-7)^2+(4-8)^2}$$$$=\sqrt{64}=8$$
将其转化为代码的结果如下:
1 | def distance(x: List[float], y: List[float]) -> float: |
太好了。我们刚刚实现了第一个构建:一个欧氏距离函数。
投票函数
接下来我们需要实现投票函数。投票函数接受一个标签列表作为输入,并返回该列表的“最常见”标签。虽然这听起来很容易实现,但我们应该后退一步,考虑可能遇到的潜在的极端情况。
其中一种情况是,我们有两个或多个“最常见”标签:
1 | # Do we return `a` or `b`? |
对于这些场景,我们需要实现一个决策机制。
有几种方法可以解决这个问题。一种解决办法可能是随机挑选一个标签。然而,在我们的例子中,我们不应该孤立地考虑投票函数,因为我们知道:距离函数和投票函数共同来确定对未分类数据的预测。
我们可以利用这一事实。假设我们的投票函数输入了一个标签列表,这个列表是按距离从近到远排序的。有了这一条件,就很容易打破平局。我们需要做的就是递归地删除列表中的最后一个条目(也就是最远的条目),直到只有一个标签明显胜出。
下面根据以上的标签示例演示此过程:
1 | # Do we return `a` or `b`? |
我们把这个算法转换成一个函数,并且称之为majority_vote:
1 | def majority_vote(labels: List[str]) -> str: |
测试表明,我们的majority_vote函数能够可靠地处理上述极端情况(边缘情况)。
K-NN算法
既然我们已经研究并编写了两个函数,现在是时候把它们结合起来了。我们即将实现的knn函数会输入带标签的数据列表、一个新的度量值(我们要分类的数据点)和一个参数k。参数k决定了:在通过majority_vote函数投票给新标签时,我们要考虑多少个邻居。
knn算法的首要任务是计算新数据点和所有其他现有数据点之间的距离。之后,我们需要从最近到最远的距离排序,并提取数据点标签。然后截断此有序列表,使其仅包含k个最近的数据点标签。最后一步是将此列表传递给投票函数,该函数用于计算预测标签。
将所述步骤转换为代码,将产生以下knn函数:
1 | def knn(labeled_data: List[LabeledData], new_measurement, k: int = 5) -> Prediction: |
就是这样。这就是从头开始实现的k近邻算法!
鸢尾花分类
现在是时候看看我们的自制k-NN实现效果是否像宣传的那样了。为了测试我们编写的代码,我们将使用臭名昭著的鸢尾花数据集。
该数据集由三种不同的鸢尾花的50个样本组成:
- Iris Setosa
- Iris Virginica
- Iris Versicolor
对每一个样品,收集了4种不同的测量数据:萼片的宽度和长度以及花瓣的宽度和长度。
下面是数据集中的一个示例行,其中前4个数字是萼片长度、萼片宽度、花瓣长度、花瓣宽度,最后一个字符串表示这些测量数据的标签。
1 | 6.9,3.1,5.1,2.3,Iris-virginica |
探索这些数据的最好方法是可视化。不幸的是,很难绘制和检查四维数据。然而,我们可以选择两个特征(如花瓣长度和花瓣宽度)并绘制二维散点图。
1 | fig = px.scatter(x=xs, y=ys, color=text, hover_name=text, labels={'x': 'Petal Length', 'y': 'Petal Width'}) |
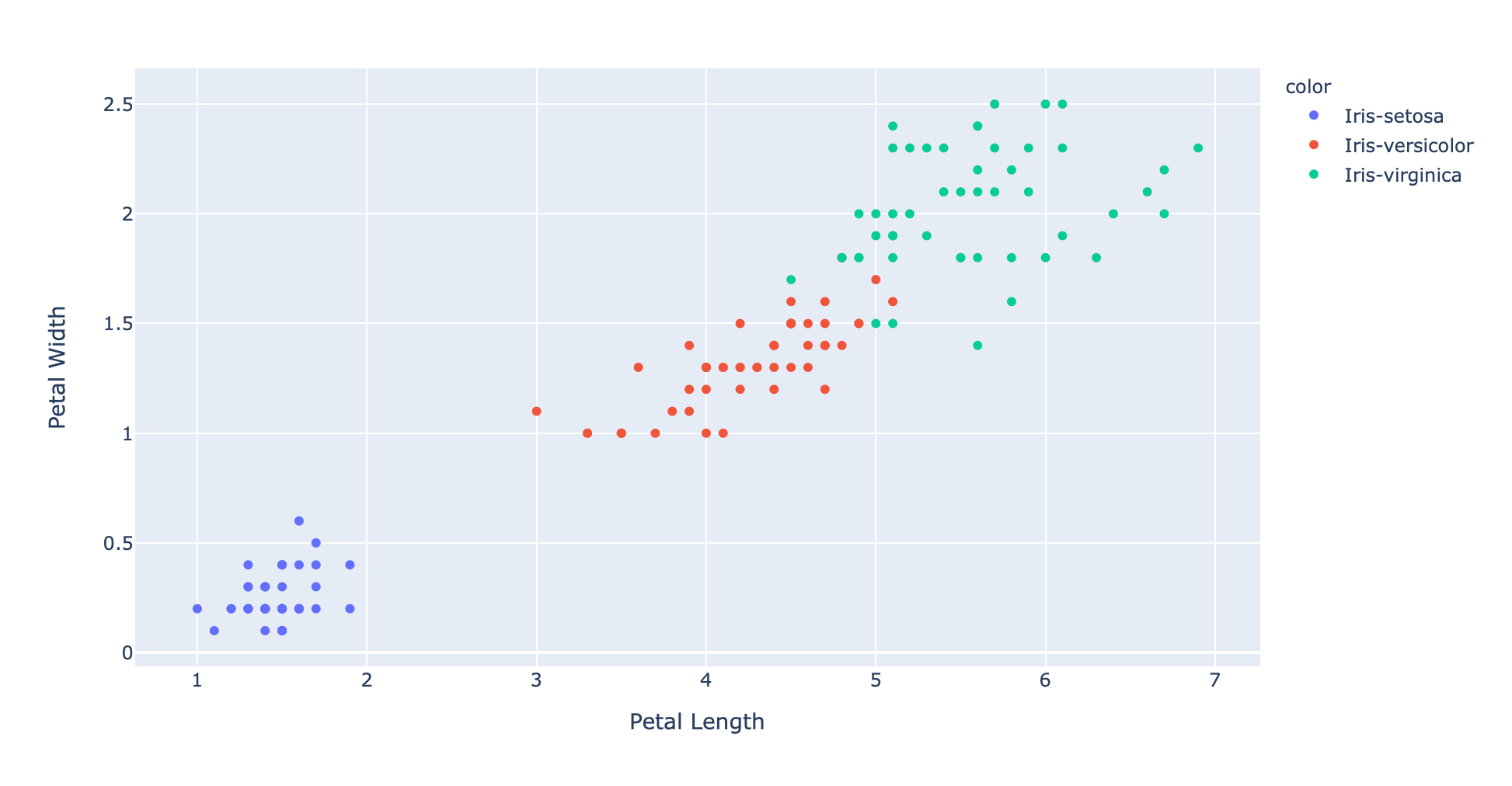
我们可以清楚地看到数据点的分类情况,每个类别的数据点有着相同的颜色,因此具有相同的标签。
现在假设我们有一个新的、未标记的数据点:
1 | new_measurement: List[float] = [7, 3, 4.8, 1.5] |
将这个数据点添加到现有的散点图,结果如下:
1 | fig = px.scatter(x=xs, y=ys, color=text, hover_name=text, labels={'x': 'Petal Length', 'y': 'Petal Width'}) |
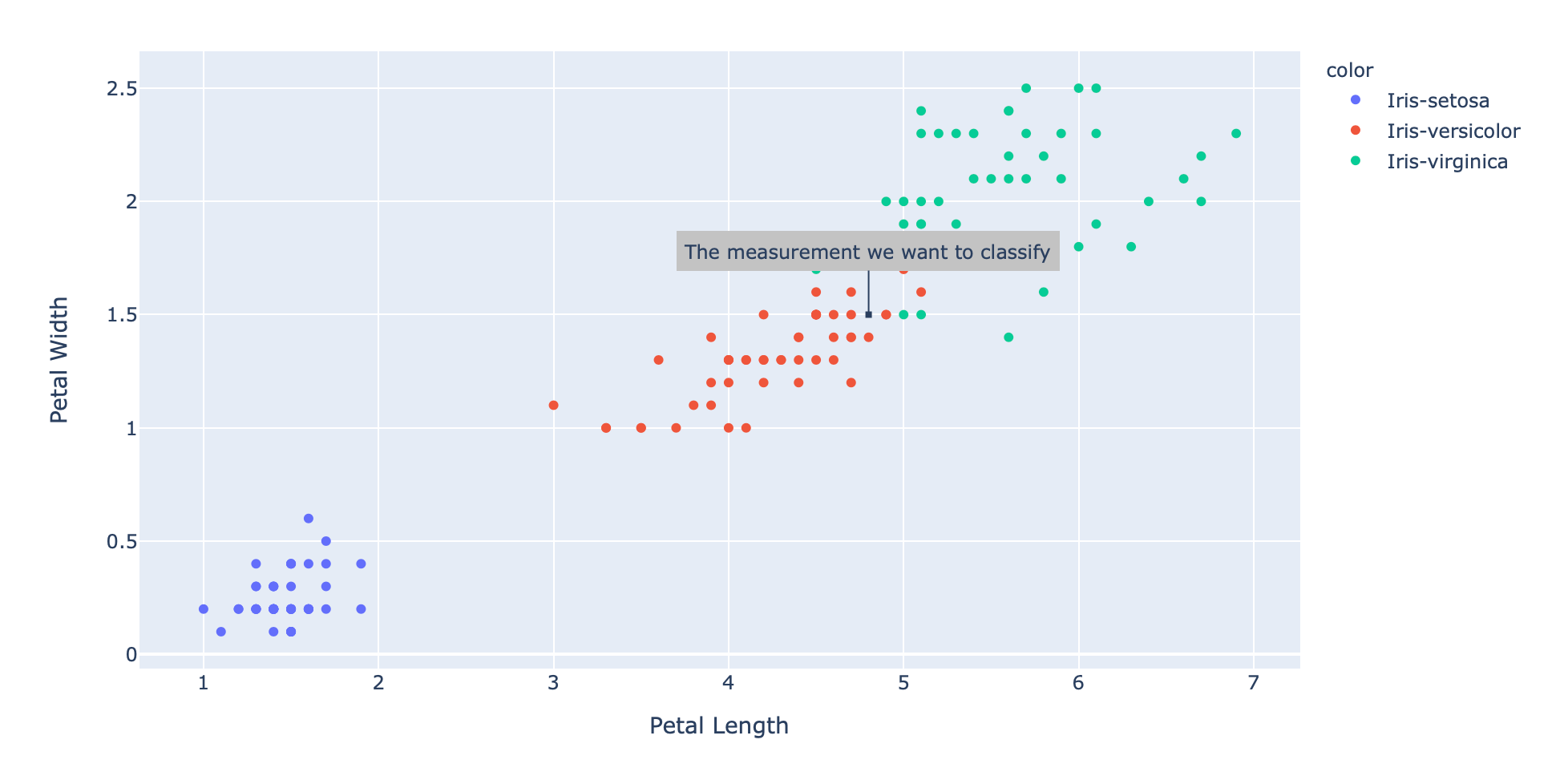
即使我们只是在二维中绘制花瓣的长度和宽度,新的测量值似乎也可能来自“变色鸢尾”。
让我们用knn函数得到一个明确的答案:
1 | knn(labeled_data, new_measurement, 5) |
果然,我们得到的结果表明,我们正在处理一个“变色鸢尾”:
1 | Prediction(label='Iris-versicolor', measurements=[7, 3, 4.8, 1.5]) |
结论
k近邻分类算法是一种非常强大的分类算法,它可以根据已有标签的数据来标记缺失标签的数据。k-NNs的主要思想是:利用新的“待分类”数据点的K个最近邻来“投票”选出它应有的标签。
因此,我们需要两个核心函数来实现k-NN。第一个函数计算两个数据点之间的距离,以便找到最近的邻居。第二个函数执行多数投票,以便可以决定哪个标签在给定的邻域中最常见。
同时使用这两个函数可以使k-NN发挥积极作用,并且可以可靠地标记未显示的数据点。
我希望这篇文章是有帮助的,它揭开了k近邻算法的内部工作原理的神秘面纱。
原文链接:https://philippmuens.com/k-nearest-neighbors-from-scratch/
搜索技术问答的公众号:老齐教室
在公众号中回复:老齐,可查看所有文章、书籍、课程。
觉得好看,就点赞转发
若你觉得我的文章对你有帮助,欢迎点击上方按钮对我打赏

关注微信公众号,读文章、听课程,提升技能