用Pandas从HTML网页中读取数据
2020-04-01
作者: Erik Marsja
翻译:老齐
与本文相关的图书推荐:《数据准备和特征工程》

本书已经在【电子工业出版社天猫旗舰店】发售
本文,我们将通过几步演示如何用Pandas的read_html函数从HTML页面中抓取数据。首先,一个简单的示例,我们将用Pandas从字符串中读入HTML;然后,我们将用一些示例,说明如何从Wikipedia的页面中读取数据。
用Python载入数据
对于数据分析和可视化而言,我们通常都要载入数据,一般是从已有的文件中导入,比如常见的CSV文件或者Excel文件。从CSV文件中读入数据,可以使用Pandas的read_csv方法。例如:
1 | import pandas as pd |
上面的方法通常用于导入结构化的数据,比如CSV或者JSON等。
我们平时更多使用维基百科的信息,它们通常是以HTML的表格形式存在。
为了获得这些表格中的数据,我们可以将它们复制粘贴到电子表格中,然后用Pandas的read_excel读取。这样当然可以,然而现在,我们要用网络爬虫的技术自动完成数据读取。
预备知识
用Pandas读取HTML表格数据,当然要先安装Pandas了。此处使用pip来安装(也可以使用其它方式,比如Anaconda, ActivePython等),安装方法pip install pandas。
注意,如果执行此命令后会自动检查pip是否需要升级,如果有必要请升级。此外,我们也会使用lxml或者BeautifulSoup4这些包,安装方法还是用pip:pip install lxml。
read_html函数
使用Pandas的read_html从HTML的表格中读取数据,其语法很简单:
1 | pd.read_html('URL_ADDRESS_or_HTML_FILE') |

以上就是read_html函数的完整使用方法,下面演示示例:
示例1
第一个示例,演示如何使用Pandas的read_html函数,我们要从一个字符串中的HTML表格读取数据。
1 | import pandas as pd |
现在,我们所得到的结果不是Pandas的DataFrame对象,而是一个Python列表对象,可以使用tupe()函数检验一下:
1 | type(df) |

示例2
在第二个示例中,我们要从维基百科中抓取数据。我们要抓取的是关于蟒科的表格数据。
1 | import pandas as pd |
现在,我们得到了一个包含7个表格的列表(len(df)),如果打开维基百科的那个网页,我们能够看到第一个表格是页面右边的,在本例中,我们更关心的是第二个表格:
1 | dfs[1] |
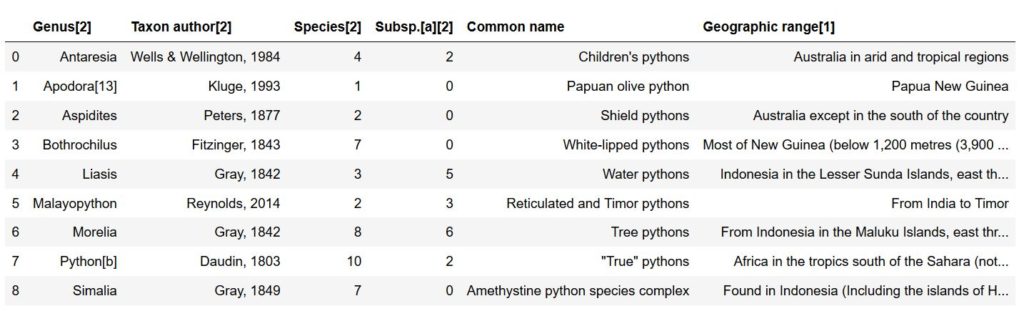
示例3
在第三个示例中,我们要读取瑞典的新冠病毒(covid-19)数据。此处,需要在read_html方法中增加一个参数,然后实施数据清洗,最后要对这些数据进行可视化。
抓取数据
打开网页,会看到页面中的表格上写着“New COVID-19 cases in Sweden by county”,现在,我们就使用match参数和这个字符串:
1 | dfs = pd.read_html('https://en.wikipedia.org/wiki/2020_coronavirus_pandemic_in_Sweden', |
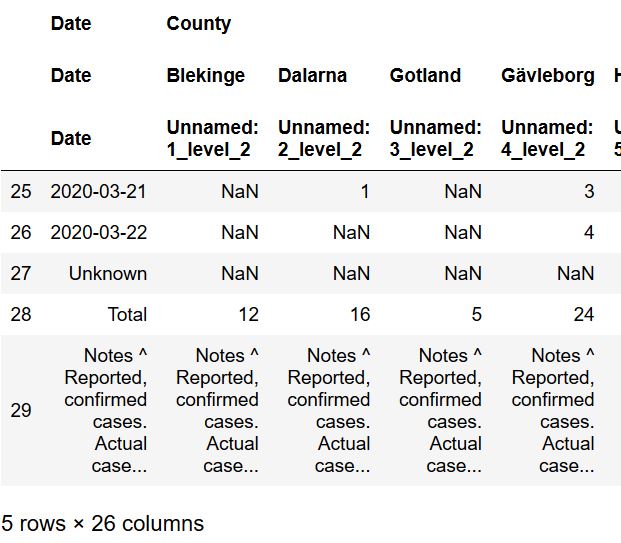
用这个方法,我们仅得到了网页上的表格,但是,如图中所示,倒数三行是没用的,需要删除它们。
用Pandas的iloc删除最后几行
下面,使用Pandas的iloc删除最后三行。注意,我们使用-3作为第二个参数(如果对此不理解,请参考Pandas有关教程,比如《跟老齐学Python:数据分析》),最后再复制一份数据。
1 | df = dfs[0].iloc[:-3, :].copy() |
接下来,要学习如何将多级列索引改为一级索引。
修改多级索引为一级,并删除不必要的字符
现在,我们要处理多级列索引问题了,准备使用DataFrame.columns和DataFrame.columns,get_level_values():
1 | df.columns = df.columns.get_level_values(1) |
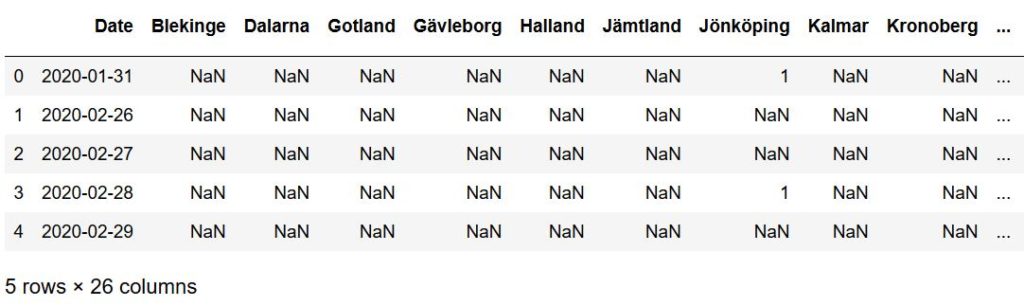
最后,如你所见,在“Date”那一列,我们用read_html从维基百科网页的表格中获得数据之后,还有一些说明,接下来使用str.replace函数和正则表达式对其进行修订:
1 | df['Date'] = df['Date'].str.replace(r"\[.*?\]","") |
用set_index更改索引
我们继续使用Pandas的set_index方法将日期列设置为索引,这样做能够为后面的作图提供一个时间类型的Series对象。
1 | df['Date'] = pd.to_datetime(df['Date']) |
为了后续的作图需要,我们需要用0填充缺失值,然后将相应列的数据类型改为数字类型。为此,使用apply方法。最后,使用cumsum()方法得到每一列的逐项求和的值。
1 | df.fillna(0, inplace=True) |
用时间Series作图
最后一部分,使用read_html所得到的数据,创建一个时间序列的图像。首先,要导入matplotlib,可以用legend函数定义图例的位置。
1 | %matplotlib inline |
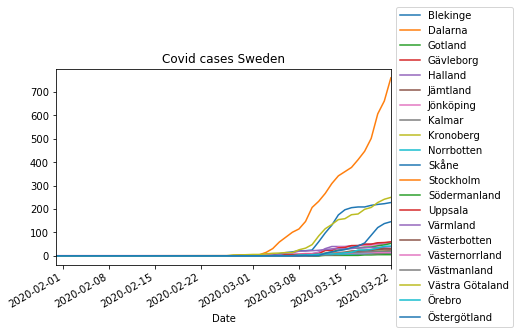
结论:如何从HTML中读取数据并转化为DataFrame类型
本文中,学习了用Pandas的read_html函数从HTML中读取数据的方法,并且,我们利用维基百科中的数据创建了一个含有时间序列的图像。不仅如此,最后还将“Date”列设置为DataFrame的索引。
原文链接:https://www.marsja.se/how-to-use-pandas-read_html-to-scrape-data-from-html-tables/
搜索技术问答的公众号:老齐教室
在公众号中回复:老齐,可查看所有文章、书籍、课程。
觉得好看,就点赞和转发
若你觉得我的文章对你有帮助,欢迎点击上方按钮对我打赏

关注微信公众号,读文章、听课程,提升技能