作者:Florian Dahlitz
翻译:老齐
与本文相关书籍推荐:《跟老齐学Python:Django实战》

我想在我的个人网站上展现我在Github上提交代码的组织名称,并且不用我手动更新提交记录的变化。Github提供了读取数据的API,但是,不能体现出我想一些开发组织提交的代码。这就是我之所以要爬取那些信息的原因。本文的代码仓库:https://github.com/DahlitzFlorian
本文中,我将向你展示一下开发过程。
准备
为了能顺利完成本文项目,请安装如下依赖。在当前目录中创建一个名为requirements.txt的文件,打开文本编辑器,把下面的内容复制到该文件中。
1
2
3
| beautifulsoup4==4.9.0
lxml==4.5.0
requests==2.23.0
|
我们使用requests获取网页内容,lxml和beautifulsoup4是另外提取信息的工具。
如果你不想把你本地的Python环境搞得太复杂,可以创建虚拟环境:
1
2
| $ python -m venv .venv
$ source .venv/bin/activate
|
然后,用pip安装requirements.txt里列出的各项依赖。
1
| $ python -m pip install -r requirements.txt
|
从HTML中找到相应的标签
首先,你要知道从哪里找到需要的信息。在本例中,我打算获取用户向Github某个特定组织的提交记录,打开用户自己Github页面,滚动如下图所示的地方。
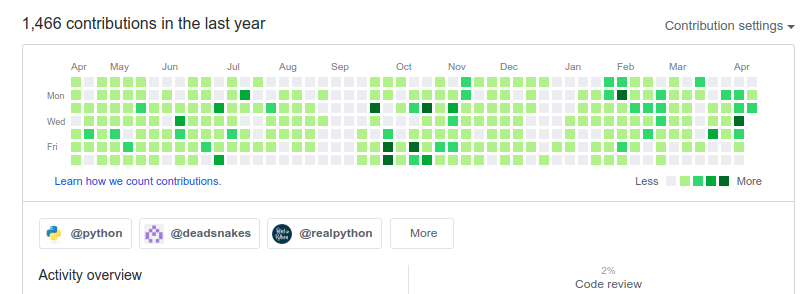
在你的浏览器上用开发和工具,打开HTML源码,并且找到对应的元素。点击某个组织,对应着看到相应源码,在<a>标签内的<nav>元素中的就是组织名称。

我们感兴趣的就在<nav>元素里面,所以,要把这个元素的class记录下来,以备后用。
1
| orgs_nav_classes = "subnav mb-2 d-flex flex-wrap"
|
你可能注意到,我忽略了其他的组织名称,后面会演示,那些组织都包含在了我们提取的信息中了。另外,我们使用这个页面上抓取数据,因为HTML代码更可靠,所有的orgs_nav_classes值都一样。
在工作目录中,创建scrape_github_orgs.py文件,其代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| # scrape_github_orgs.py
import requests
from bs4 import BeautifulSoup
from bs4.element import ResultSet
orgs_nav_classes = "subnav mb-2 d-flex flex-wrap"
def get_user_org_hyperlinks(username: str) -> ResultSet:
url = f"https://github.com/users/{username}/contributions"
page = requests.get(url)
soup = BeautifulSoup(page.content, "html.parser")
nav = soup.find("nav", class_=orgs_nav_classes)
tmp_orgs = nav.find_all("a")
return tmp_orgs
print(get_user_org_hyperlinks("DahlitzFlorian"))
|
首先,引入需要的requests库,还有bs4中的BeautifulSoup。然后,定义函数get_user_org_hyperlinks(),它的参数是username,返回元素<nav>的值是 orgs_nav_classes的所有内容。最后一行,调用get_user_org_hyperlinks()函数,并且把结果打印出来。
执行脚本,得到如下信息:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| $ python scrape-github-orgs.py
[<a class="js-org-filter-link f6 py-1 pr-2 pl-1 rounded-1 mr-2 mb-2 subnav-item css-truncate css-truncate-target" data-hovercard-type="organization" data-hovercard-url="/orgs/python/hovercard" data-hydro-click='{"event_type":"user_profile.highlights_click","payload":{"scoped_org_id":null,"target_type":"ORGANIZATION","target_url":"/DahlitzFlorian?tab=overview&org=python","originating_url":"https://github.com/users/DahlitzFlorian/contributions","user_id":null}}' data-hydro-click-hmac="3663f0f1c5ecdf3ad7c4ccbf2ecaea5470a15408175ebcb137f286fd900fc30b" href="/DahlitzFlorian?tab=overview&org=python" style="max-width: 181px;">
<img alt="" class="avatar mr-1" height="20" src="https://avatars1.githubusercontent.com/u/1525981?s=60&v=4" width="20"/>
@python
</a>, <a class="js-org-filter-link f6 py-1 pr-2 pl-1 rounded-1 mr-2 mb-2 subnav-item css-truncate css-truncate-target" data-hovercard-type="organization" data-hovercard-url="/orgs/deadsnakes/hovercard" data-hydro-click='{"event_type":"user_profile.highlights_click","payload":{"scoped_org_id":null,"target_type":"ORGANIZATION","target_url":"/DahlitzFlorian?tab=overview&org=deadsnakes","originating_url":"https://github.com/users/DahlitzFlorian/contributions","user_id":null}}' data-hydro-click-hmac="2e0501a07d2125d7a4baad8faa6ad0c122f0f666c517db46acaed474cc87689b" href="/DahlitzFlorian?tab=overview&org=deadsnakes" style="max-width: 181px;">
<img alt="" class="avatar mr-1" height="20" src="https://avatars3.githubusercontent.com/u/31392125?s=60&v=4" width="20"/>
@deadsnakes
</a>, <a class="js-org-filter-link f6 py-1 pr-2 pl-1 rounded-1 mr-2 mb-2 subnav-item css-truncate css-truncate-target" data-hovercard-type="organization" data-hovercard-url="/orgs/realpython/hovercard" data-hydro-click='{"event_type":"user_profile.highlights_click","payload":{"scoped_org_id":null,"target_type":"ORGANIZATION","target_url":"/DahlitzFlorian?tab=overview&org=realpython","originating_url":"https://github.com/users/DahlitzFlorian/contributions","user_id":null}}' data-hydro-click-hmac="7d9cf37efc7d25bf36c85a17b01f15138f6261575347d3f139283056adce6043" href="/DahlitzFlorian?tab=overview&org=realpython" style="max-width: 181px;">
<img alt="" class="avatar mr-1" height="20" src="https://avatars1.githubusercontent.com/u/5448020?s=60&v=4" width="20"/>
@realpython
</a>, <a class="d-block select-menu-item wb-break-all js-org-filter-link" data-hydro-click='{"event_type":"user_profile.highlights_click","payload":{"scoped_org_id":null,"target_type":"ORGANIZATION","target_url":"/DahlitzFlorian?tab=overview&org=PyCQA","originating_url":"https://github.com/users/DahlitzFlorian/contributions","user_id":null}}' data-hydro-click-hmac="2080f6ec3d42f9ac04eabafad7c72805d26acb10c822037397fd5bd1dafd5da0" href="/DahlitzFlorian?tab=overview&org=PyCQA" role="menuitem" style="padding: 8px 8px 8px 30px;">
<img alt="" class="select-menu-item-icon mr-2" height="20" src="https://avatars1.githubusercontent.com/u/8749848?s=60&v=4" width="20"/>
<div class="select-menu-item-text css-truncate css-truncate-target" style="max-width: 95%;">@PyCQA</div>
</a>]
|
下面进入信息提取阶段。
提取必要的信息
记住,我们想获得某个用户提交代码的Github上的组织名称,已经得到了包含组织名称的超链接,然而,其中有很多我们不需要的样式类和属性,接下来就要清除它们,利用lxm包(lxml.html.clean.Cleaner)中的Cleaner()实现这个操作。首先,移除比必要的属性,为此创建一个Cleaner的实例,然后设置实例属性safe_attrs_only=True的值为True,与其关联的属性safe_attrs,利用frozenset创建一个不可变对象,并作为此属性的值。
1
2
3
4
5
| from lxml.html import clean
cleaner = clean.Cleaner()
cleaner.safe_attrs_only = True
cleaner.safe_attrs = frozenset(["class", "src", "href", "target"])
|
上面的三行代码定义了cleaner对象,但是还没有对HTML采取行动,这要留作后用。接下来,我们要编写一个匹配所有HTML标签的正则表达式,因此要使用Python的re模块。
1
2
3
| import re
html_tags = re.compile("<.*?>")
|
最后,开始按照我们的需要实施清除操作。
1
2
3
4
5
6
7
8
9
| orgs = []
for org in tmp_orgs:
tmp_org = str(org)
org_name = re.sub(
html_tags,
"",
re.search(r"<a(.*)@(.*)</a>", tmp_org, flags=re.DOTALL).group(2).strip(),
)
|
orgs是一个列表,把我们打算在网站上呈现的Github组织的超链接放到它里面,每次循环到我们抓取到的超链接,就会将其增加到列表中,上面的代码片段,就是把每个组织的超链接追加到列表中。我们需要的是字符串,不是bs4原酸,要将每个超链接转化为字符串,并且用变量temp_org引用。然后,用re的sub()函数从超链接中提取组织的名称。
现在,得到了所有组织的名称。太棒了!让我们再按照我们的网站能用的格式获得超链接,利用lxml.html.fromstring()函数,将temp_org的超链接转化为lxml中的树。
1
2
3
4
5
6
7
8
9
10
11
| import lxml
from lxml import etree
tree = lxml.html.fromstring(tmp_org)
tree.attrib["href"] = f"https://github.com/{org_name}"
tree.attrib["class"] = "org"
tree.set("target", "_blank")
etree.strip_tags(tree, "div")
cleaned = cleaner.clean_html(tree)
orgs.append(lxml.html.tostring(cleaned).decode("utf-8"))
|
每个组织的地址都符合https://github.com/org_name格式,org_name就是组织名称,用attrib属性,把这个链接地址作为树状结构的元素。为了便于后续页面风格的设计,我们增加了一个CSS,相应名称为org。当点击超链接的时候,我想在浏览器中打开一个新的tab,于是设置了target='blank'。
etree.strip_tags(tree, "div")能够从树状结构中删除<div>元素,这是很有必要的,因为组织名称常常在<div>标签包括的超链接中,不需要这些标签,所以要删除。还要做下面两步:第一,利用cleaner删除所有不必要的<a>标签元素;第二,利用lxml.html.tostring()把树状结构的元素转化为字符串,然后追加到orgs列表中(我们使用的是UTF-8编码)。

把上面的过程写成函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| import re
from typing import List
import lxml
from bs4.element import ResultSet
from lxml import etree
from lxml.html import clean
def extract_orgs(tmp_orgs: ResultSet) -> List[str]:
cleaner = clean.Cleaner()
cleaner.safe_attrs_only = True
cleaner.safe_attrs = frozenset(["class", "src", "href", "target"])
html_tags = re.compile("<.*?>")
orgs = []
for org in tmp_orgs:
tmp_org = str(org)
org_name = re.sub(
html_tags,
"",
re.search(r"<a(.*)@(.*)</a>", tmp_org, flags=re.DOTALL).group(2).strip(),
)
tree = lxml.html.fromstring(tmp_org)
tree.attrib["href"] = f"https://github.com/{org_name}"
tree.attrib["class"] = "org"
tree.set("target", "_blank")
etree.strip_tags(tree, "div")
cleaned = cleaner.clean_html(tree)
orgs.append(lxml.html.tostring(cleaned).decode("utf-8"))
return orgs
|
然后,将抓取和提取两个阶段写成一个函数:
1
2
3
| def get_user_orgs(username: str) -> List[str]:
tmp_orgs = get_user_org_hyperlinks(username)
return extract_orgs(tmp_orgs)
|
最后看看我们辛苦工作的结果,在脚本的末尾把最终结果打印出来。下面是最终的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
| # scrape_github_orgs.py
import re
from typing import List
import lxml
import requests
from bs4 import BeautifulSoup
from bs4.element import ResultSet
from lxml import etree
from lxml.html import clean
orgs_nav_classes = "subnav mb-2 d-flex flex-wrap"
def get_user_org_hyperlinks(username: str) -> ResultSet:
url = f"https://github.com/users/{username}/contributions"
page = requests.get(url)
soup = BeautifulSoup(page.content, "html.parser")
nav = soup.find("nav", class_=orgs_nav_classes)
tmp_orgs = nav.find_all("a")
return tmp_orgs
def extract_orgs(tmp_orgs: ResultSet) -> List[str]:
cleaner = clean.Cleaner()
cleaner.safe_attrs_only = True
cleaner.safe_attrs = frozenset(["class", "src", "href", "target"])
html_tags = re.compile("<.*?>")
orgs = []
for org in tmp_orgs:
tmp_org = str(org)
org_name = re.sub(
html_tags,
"",
re.search(r"<a(.*)@(.*)</a>", tmp_org, flags=re.DOTALL).group(2).strip(),
)
tree = lxml.html.fromstring(tmp_org)
tree.attrib["href"] = f"https://github.com/{org_name}"
tree.attrib["class"] = "org"
tree.set("target", "_blank")
etree.strip_tags(tree, "div")
cleaned = cleaner.clean_html(tree)
orgs.append(lxml.html.tostring(cleaned).decode("utf-8"))
return orgs
def get_user_orgs(username: str) -> List[str]:
tmp_orgs = get_user_org_hyperlinks(username)
return extract_orgs(tmp_orgs)
print(get_user_orgs("DahlitzFlorian"))
|
执行脚本之后的输出:
1
2
| $ python scrape_github_orgs.py
['<a class="org" href="https://github.com/python" target="_blank">\n<img class="avatar mr-1" src="https://avatars1.githubusercontent.com/u/1525981?s=60&v=4">\n @python\n</a>', '<a class="org" href="https://github.com/deadsnakes" target="_blank">\n<img class="avatar mr-1" src="https://avatars3.githubusercontent.com/u/31392125?s=60&v=4">\n @deadsnakes\n</a>', '<a class="org" href="https://github.com/realpython" target="_blank">\n<img class="avatar mr-1" src="https://avatars1.githubusercontent.com/u/5448020?s=60&v=4">\n @realpython\n</a>', '<a class="org" href="https://github.com/PyCQA" target="_blank">\n<img class="select-menu-item-icon mr-2" src="https://avatars1.githubusercontent.com/u/8749848?s=60&v=4">\n@PyCQA\n</a>']
|
相当满意!抓取到了你贡献代码的Github上的组织,并且提取了所需要的信息,然后把这些内容发布到你的网站上。让我们来看一下,在网站上的显示样式,跟Github上的差不多。
网站上的显示方式
这里我们使用Jinjia2渲染前端,用for玄幻将orgs中的每个元素循环出来。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| <!DOCTYPE html>
<html lang="en">
<head>
<title>GitHub Organizations</title>
<link rel="stylesheet" type="text/css" href="/static/css/main.css">
</head>
<body>
<div class="orgs">
{% for org in orgs %}
{{ org | safe }}
{% endfor %}
</div>
</body>
</html>
|
我用Flask作为网站框架(python -m pip install flask==1.1.2),可以参考本文在Github上的代码仓库。下面是为网站增加样式表:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| div.orgs {
display: flex;
flex-direction: row;
flex-wrap: wrap;
align-items: center;
justify-content: center;
margin-top: 15px;
}
a.org {
background-color: #fff;
border: 1px solid #e1e4e8;
border-radius: 3px;
padding: 7px;
margin: 10px;
color: #586069;
text-decoration: none;
display: flex;
align-items: center;
}
a.org:hover {
background-color: #f6f8fa;
}
a.org > img {
margin-right: 5px;
max-height: 25px;
}
|
把网站跑起来之后,就呈现下面的效果:

总结
在本文中,我们学习了从网站上抓取内容的方法,并且从中提取你需要的信息,然后将这些内容根据要求显示在网页上。这是一个爬虫示例,并且用Jinja2模板展示结果。
希望能对你有用。在本公众号还有很多爬虫公开课,在公众号中回复:老齐,可以找到公开课列表。
原文链接:https://florian-dahlitz.de/blog/scrape-github-orgs-using-python
搜索技术问答的公众号:老齐教室
在公众号中回复:老齐,可查看所有文章、书籍、课程。
觉得好看,就点这里👇👇👇
