用Python读取Excel文件指南
2020-06-11
原作者:Erik Marsja
编译者:老齐
与本文相关的图书推荐:《数据准备和特征工程》

本书适合于数据科学、机器学习、深度学习等方向的学习者阅读。书中通过案例的形式,系统阐述了数据获取、数据整理、特征工程、特征选择等方法。
本文,将重点阐述用Python如何读取Excel文件(xlsx),重点是演示使用openpyxl模块读取xlsx类型的文件。首先,我们要看一些简单的示例;然后,我们将学习读取多个Excel文件。
如果你阅读过《数据准备和特征工程》(电子工业出版社出版)这本书,就肯定知道,在书中,作者介绍了如何使用Pandas读取Excel文件。在阐述本文的同时,你所看到的书中的方法,依然有效且常用。本文的目的主要是要介绍另外一种方法,并且这种方法也有它的特点。
Openpyxl简介
openpyxl模块的官方网站是:https://openpyxl.readthedocs.io/en/stable/。这里,先演示一个简单的示例,看看在Python语言中如何用openpyxl模块读取一个xlsx文件。
1 | import openpyxl |
当然,在理解上面代码之前,你应该已经知道如何读写文件了,如果这方面尚有不足,请阅读《跟老齐学Python:轻松入门》中的有关章节。
为了能够使用openpyxl模块,请先确认,在本地已经安装了Python3和这个模块。模块的安装方法非常简单,即:pip install openpyxl,如果你使用的是conda,还可以:conda install openpyxl。注意,使用pip安装的时候,如果提示你不是最新版本,应该尽快升级,用最新版本的pip来安装。
读取单个文件
前面的代码中,已经读取了单个文件,下面我们更详细地对代码进行解读。
- 引入模块
读取xlsx文件的第一步,就是要引入必要的模块,这里我们引入了Path和openpyxl两个模块。
1 | import openpyxl |

- 设置Excel文件路径
在这一步,我们用Path创建了一个实例,并且用变量xlsx_file引用,它包含了文件的路径和文件名称。
1 | # Setting the path to the xlsx file: |
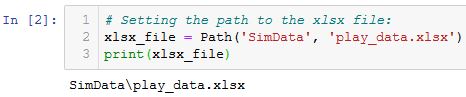
注意,代码中的SimData是当前工作目录的子目录,本例中的Excel文件保存在该目录中,如果保存在了其他目录中,需要设置完整的文件路径,例如:xlsx_file = Path(Path.home(), 'Documents', 'SimData', 'play_data.xlsx'),这是将Excel文件保存到了Documents目录里面的SimData子目录中了。
- 读入Excel文件(工作簿)
第三步,利用load_workbook()方法读取文件:
1 | wb_obj = openpyxl.load_workbook(xlsx_file) |

打印输出结果说明,当前得到的是工作簿对象。
- 从Excel文件中读入当前工作表
一个工作簿,有多个工作表。我们能够使用的是当前的工作表,可以用下面的方式获得:
1 | wsheet = wb_obj.active |

如果知道了工作表名称,可以用这种方式得到指定工作表play_data = wb_obj['play_data']。这样就能够实现工作表的切换。
- 操作工作表
现在可以编辑工作表了,例如,用下面的方式获得指定单元格的值。
1 | print(sheet["C2"].value) |
再如,对于已经读取到的工作表,我们能够用循环语句获得指定行,并且把各个单元格中的值打印出来。
1 | for row in sheet.iter_rows(max_row=6): |
注意,上面代码中的参数max_row,其值为6,意味着读取这个工作表的前6行。
- 补充:输出行和列的数量
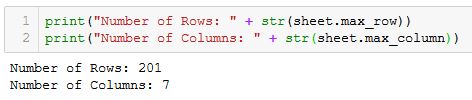
再补充一个常用操作,就是确定Excel文件的行和列的数量。
1 | print(sheet.max_row, sheet.max_column) |
将读入的Excel文件保存为Python字典
把Excel文件的内容读入之后,怎么将它保存为字典对象?
有时候,你可能需要得到列的名称,下面代码就演示了如何实现这种需求。
1 | import openpyxl |
为了将Excel内容保存为字典对象,当然要创建一个字典,然后就是通过循环的方式,向字典中增加相应内容。
1 | data = {} |
在上面的代码中,创建了一个字典data,然后玄幻每一行(iter_rows),并且仅仅获取该行的值。接下来使用条件语句,判断一下,如果是第一行,就增加字典的键,这其实是以键为列的名称。否则,将根据键(加Excel中的每一列)向字典中增加值。
读取多个Excel文件
下面,我们要用openpyxl模块读取多个xlsx文件。
- 导入模块
除了前面使用过的恋歌模块之外,增加了一个glob。
1 | import glob |
- 读取目录中的所有xlsx文件
假设在子目录中有多个xlsx文件,现在我们使用glob模块,将它们都读入:
1 | xlsx_files = [path for path in Path('XLSX_FILES').rglob('*.xlsx')] |
- 创建工作簿对象
现在已经读入了所有xlsx文件,接下来还是使用load_workbook方法创建工作簿对象,不过,这次要使用列表解析的方式循环了。
1 | wbs = [openpyxl.load_workbook(wb) for wb in xlsx_files] |
这个列表中包含了所有xlsx文件的工作簿对象。
- 操纵每个文件
所有的工作簿对象都保存到了wbs引用的列表中,比如乣得到第一个工作簿,可以用wbs[0],它的默认工作表名称,可以用wbs[0].sheetnames得到。其他操作跟前面就没有什么差别了。这样我们就能读入多个Excel文件了。
参考链接:https://www.marsja.se/your-guide-to-reading-excel-xlsx-files-in-python/
若你觉得我的文章对你有帮助,欢迎点击上方按钮对我打赏

关注微信公众号,读文章、听课程,提升技能