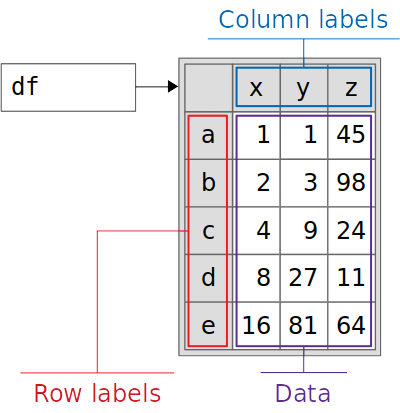
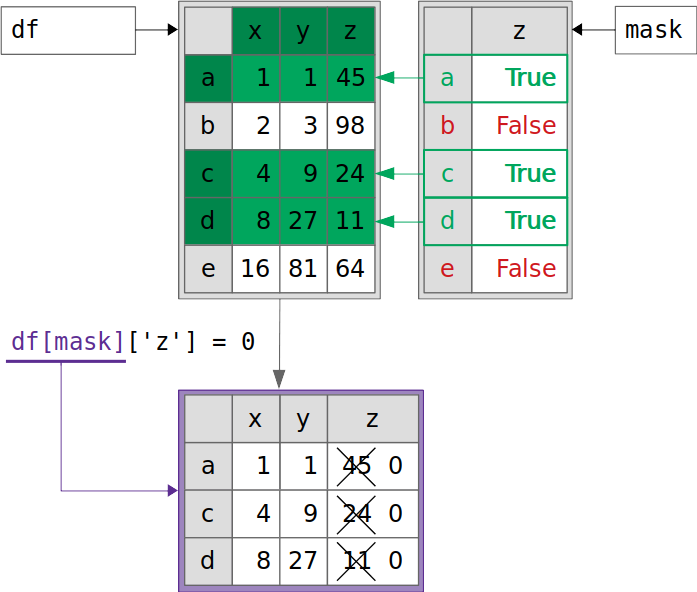
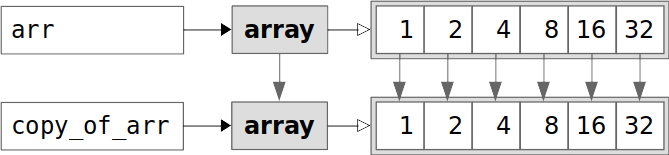
>>> df[mask]["z"] = 0 __main__:1: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame. Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
>>> df x y z a 1145 b 2398 c 4924 d 82711 e 168164
代码的执行结果显示,操作失败,没有能够将筛选出来的记录中的z列数值修改为0。这是为什么?
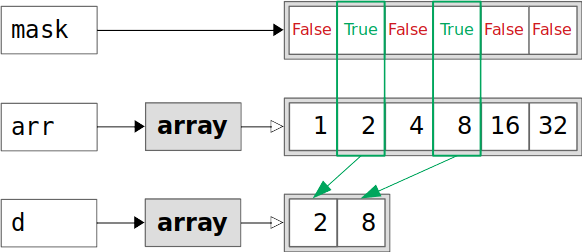
还是用图示的方式展现一下上面的操作——虽然失败了,目的是与后面的操作进行对比:
其实,一般情况下,你不用这么做,只需要按照下面的方式做就能够达到目的了:
1 2 3 4 5 6 7 8 9 10
>>> df = pd.DataFrame(data=data, index=index)
>>> df.loc[mask, "z"] = 0 >>> df x y z a 1 1 0 b 2 3 98 c 4 9 0 d 8 27 0 e 16 81 64
还有别的方式,也能实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
>>> df = pd.DataFrame(data=data, index=index)
>>> df["z"] a 45 b 98 c 24 d 11 e 64 Name: z, dtype: int64
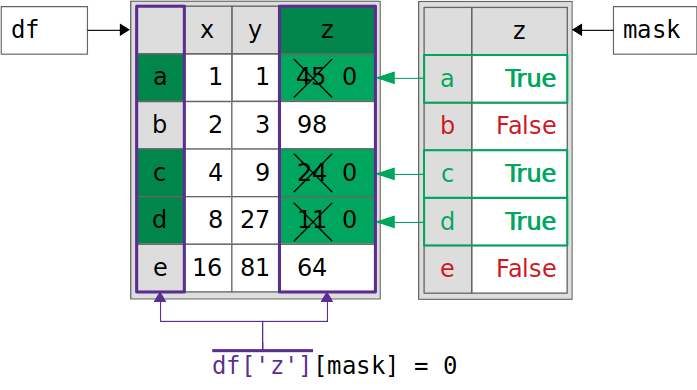
>>> df["z"][mask] = 0 >>> df x y z a 1 1 0 b 2 3 98 c 4 9 0 d 8 27 0 e 16 81 64
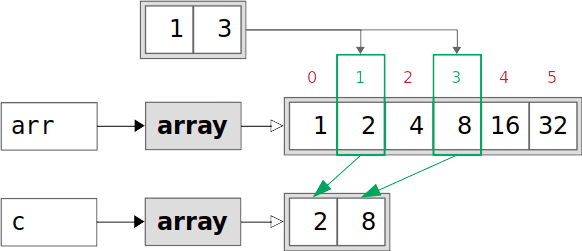
是不是感觉有点奇怪了。还是看看上面的操作流程:
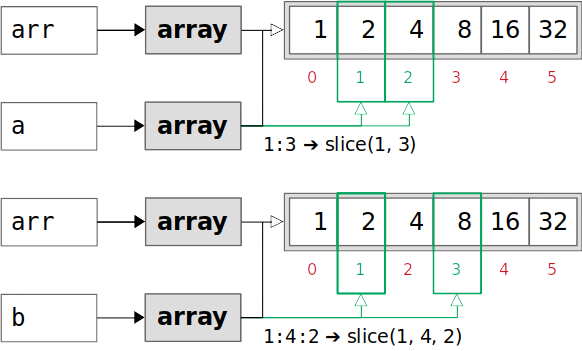
这张图和前面的图对比一下,似乎也只是下标的顺序不同罢了。是不是感觉有点复杂?还有呢,继续看:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
>>> df = pd.DataFrame(data=data, index=index)
>>> df.loc[mask]["z"] = 0 __main__:1: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame. Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy >>> df x y z a 1 1 45 b 2 3 98 c 4 9 24 d 8 27 11 e 16 81 64
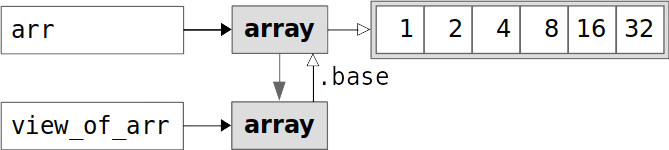
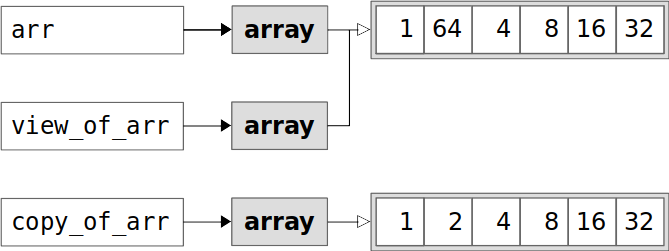
arr and copy_of_arr hold 144 bytes each. As you’ve seen previously, 48 bytes out of the 144 total are for the data elements. The remaining 96 bytes are for other attributes. view_of_arr holds only those 96 bytes because it doesn’t have its own data elements.
>>> df = pd.DataFrame(data=data, index=index) >>> mask = df["z"] < 50 >>> mask a True b False c True d True e False Name: z, dtype: bool
>>> df[mask]["z"] = 0 __main__:1: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame. Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
>>> df x y z a 1145 b 2398 c 4924 d 82711 e 168164
>>> df = pd.DataFrame(data=data, index=index) >>> df.loc[mask]["z"] = 0 __main__:1: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame. Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy >>> df x y z a 1 1 45 b 2 3 98 c 4 9 24 d 8 27 11 e 16 81 64
因为df.loc[mask]返回的还是一个拷贝,跟前面的意思一样。
如果这样做,就能成功:
1 2 3 4 5 6 7 8
>>> df["z"][mask] = 0 >>> df x y z a 1 1 0 b 2 3 98 c 4 9 0 d 8 27 0 e 16 81 64
有的时候Pandas可能不会针对拷贝报错,比如:
1 2 3 4 5 6 7 8 9
>>> df = pd.DataFrame(data=data, index=index) >>> df.loc[["a", "c", "e"]]["z"] = 0 # 这么写也不能实现修改,但不抛出异常 >>> df x y z a 1 1 45 b 2 3 98 c 4 9 24 d 8 27 11 e 16 81 64
>>> df = pd.DataFrame(data=data, index=index) >>> df[:3]["z"] = 0 # 操作成功,但是有异常抛出 __main__:1: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame. Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
>>> df x y z a 1 1 0 b 2 3 0 c 4 9 0 d 8 27 11 e 16 81 64
>>> df = pd.DataFrame(data=data, index=index) >>> df.loc["a":"c"]["z"] = 0 # 操作成功,但是有异常抛出 __main__:1: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame. Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy >>> df x y z a 1 1 0 b 2 3 0 c 4 9 0 d 8 27 11 e 16 81 64
通常,对于上述示例中的操作意图,使用.loc实现,并且是按照下面的方式:
1 2 3 4 5 6 7 8 9
>>> df = pd.DataFrame(data=data, index=index) >>> df.loc[mask, "z"] = 0 >>> df x y z a 1 1 0 b 2 3 98 c 4 9 0 d 8 27 0 e 16 81 64