根据条件增加DataFrame的列
2020-08-14
编译:老齐
与本文有关的图书推荐:《跟老齐学Python:数据分析》
当我们使用Python进行数据分析时,有时可能需要向DataFrame添加列,所添加的列要基于DataFrame的其他列的值。
虽然这听起来很简单,但是,不少初学想到的是用if-else条件语句来实现,这就把问题搞复杂了。有一个简单又有效的方法,下面就来看看这种方法如何使用。
加载一个数据集。
1 | import pandas as pd |
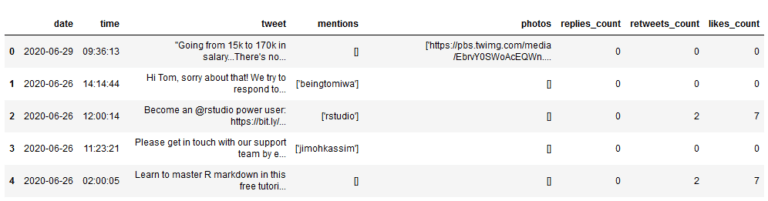
数据集的各个特征含义是:
- date:推文的发布日期
- time:推文发布的时间
- tweet:推文的文本内容
- mentions:推文中提到的其他推特用户
- photos:推文中所有图像的网址
- replies_count:推文的回复数
- retweets_count:推文的转发次数
- likes_count:推文的点赞数
注意,photos特征的数据格式有点怪。
添加一列
在接下来的数据分析中,我们要看看带有图像的推文是否更吸引人,因此,实际上不需要图像文件的地址,只需要有一个特征,用以标明该样本是否含有图像即可。于是,创建一个名为hasimage的列,其中的值为:True——包含图像,False——不包含图像。
为此,使用Numpy的内置where()函数。这个函数依次接受三个参数:条件;如果条件为真,分配给新列的值;如果条件为假,分配给新列的值。
1 | np.where(condition, value if condition is true, value if condition is false) |
在数据集中,没有图像的推文在photos列中的值总是[]。
1 | df['hasimage'] = np.where(df['photos']!= '[]', True, False) |
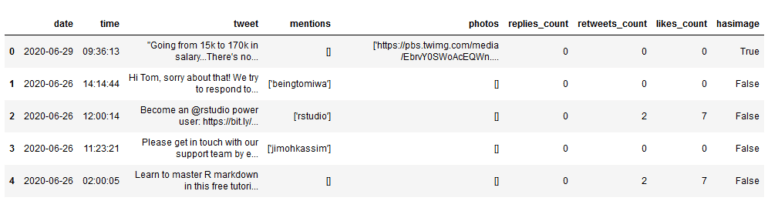
如此,在数据集中新增加了一列,并且它正确地将包含图像的推文标记为True,其他的标记为False。
现在已经有了hasimage列。再将有图文和无图文的两种类型的样本分别筛选出来:
1 | image_tweets = df[df['hasimage'] == True] |
然后比较两类推文平均点赞数。
1 | ## LIKES |
看来,有图像似乎可以让更多人来点赞。
再复杂一些
如果我们根据点赞的数量,将样本划分出不同等级,如:
- tier_4 — 2个或更少的赞数
- tier_3 — 3-9个赞数
- tier_2 — 10-15个赞数
- tier_1 — 16个以上的赞数
为此,使用一个名为np.select()的函数,给它提供两个参数:一个条件,另一个对应的等级列表。在conditions列表中的第一个条件得到满足,values列表中的第一个值将作为新特征中该样本的值,以此类推。具体代码如下:
1 | # create a list of our conditions |
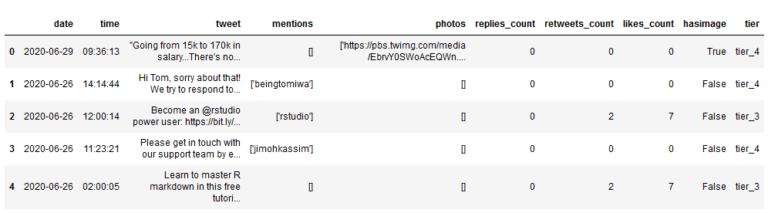
这样,特征tier就标记了样本的等级,也可以理解为将样本离散化。于是,可以用它来回答与数据集有关的更多问题。例如:第1级和第4级有百分之多少的推文带有图像?
1 | #tier 4 tweets |
1 | False 0.948784 |
1 | #tier 1 tweets |
1 | False 0.836842 |
在这里,我们可以看到,虽然图像似乎有助于吸引关注,但它们似乎不是成功的必要条件。超过83%的“一级”推文——有16个以上点赞的推文——没有附带图片。
虽然这是一个非常肤浅的分析,但我们已经实现了真正的目标:根据已知数据的条件向DataFrame添加列。
当然,这是一项可以通过多种方式来完成的任务。np.where()和np.select()只是其中的两种。这方面更多的内容,可以参考《跟老齐学Python:数据分析》一书。
参考链接:https://www.dataquest.io/blog/tutorial-add-column-pandas-dataframe-based-on-if-else-condition/
若你觉得我的文章对你有帮助,欢迎点击上方按钮对我打赏

关注微信公众号,读文章、听课程,提升技能