Jupyter不断演进的三大动力
2020-03-15
作者:LJ MIRANDA
翻译:老齐
与本文相关的书籍:《跟老齐学Python:数据分析》《数据准备和特征工程》


数据科学的发展状况
数据科学领域日新月异,在当今时代,用诸如“21世纪最性感的工作”和“数据是新的石油”等说法来强化数据科学,已经并不时髦了,取而代之的是更现实的商业问题和更理性的技术挑战,数据科学所面对的变化,就是这两个方面。因此,现在需要我们做的:(1)分析来自生产和实验的需求,(2) 云技术的快速应用。
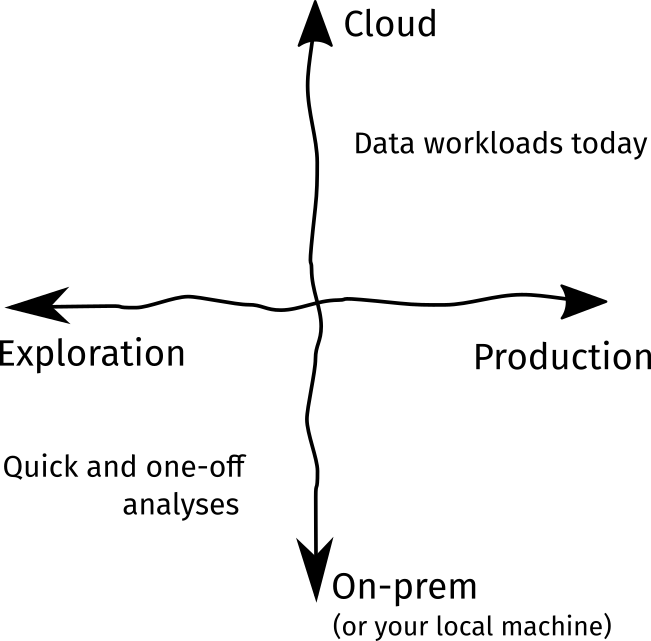
首先,生产需求多年来一直在增长。例如:在软件工程生命周期内创建数据产品或发布实验产品。随着机器学习工程师和数据科学软件开发人员的崛起,出现了越来越多的工程类就业岗位,这就是明证。此外,数据分析不再局限于把图表印刷出来,在产品发布、实验过程的重现等方面都有广泛需求,并且这种需求不断增长。
其次,数据的指数增长使云计算成为大势所趋。我们无法用自己的笔记本电脑加载1TB的数据集!Docker和Kubernetes等工具的流行,使我们能够以前所未有的水平扩大数据处理的工作量。使用云技术,意味着我们要考虑系统的可伸缩、资源配置和有关基础设施。然而,尽管之前的Jupyter生态系统是数据科学家工具箱的一个主要组成部分,但它并不适用于这些变化:
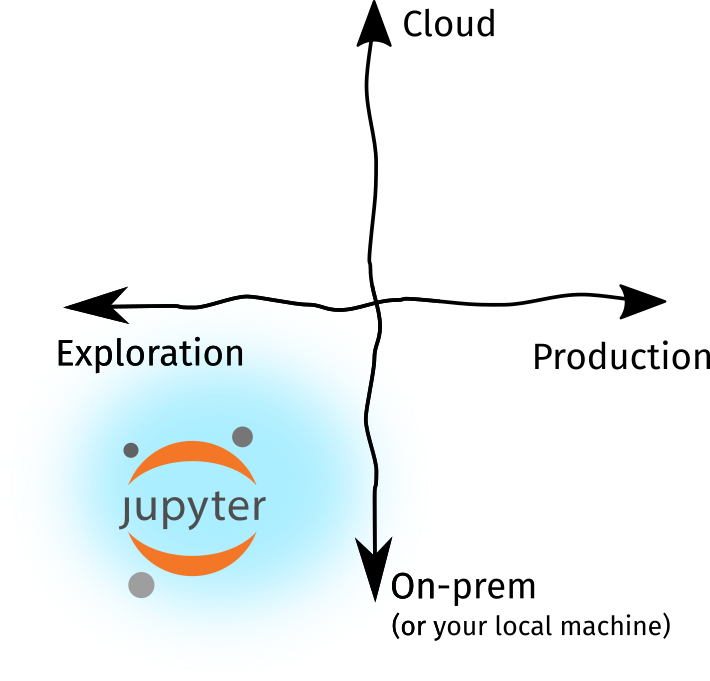
正如我说过的,我们所知道的Jupyter并不适用于这些变化。Jupyter生态系统适合探索,不适合生产。庞大的数据应该在一台机器上、而不是在一组机器上运行。然而,在过去的五年中,Jupyter的生态系统已经发展壮大。我们现在有了JupyterLab、一些插件、用于其他语言的新内核,以及可供我们使用的第三方工具。当然,我们仍然可以通过在终端中键入jupyter notebook来运行,但是现在这种做法已经远远不能满足需求了!
这就引出了一个问题:是什么力量促成了这些变化?,我们如何利用这个更大的notebook生态系统来应对当今数据科学的变化?
三股变革的力量
Jupyter笔记本电脑生态系统正在成长,我认为这是由三种力量驱动的:
云平台:大数据需要大量的计算和存储,而普通消费者所用的机器并不总是能够满足需要。
开发环境:越来越多的数据科学团队开始采用软件工程的最佳实践方案——git、pull requests等版本管理操作。
从分析到生产的快速推进:在受控环境下检验假设是不够的,为分析而编写的软件应易于在产品中重复使用。
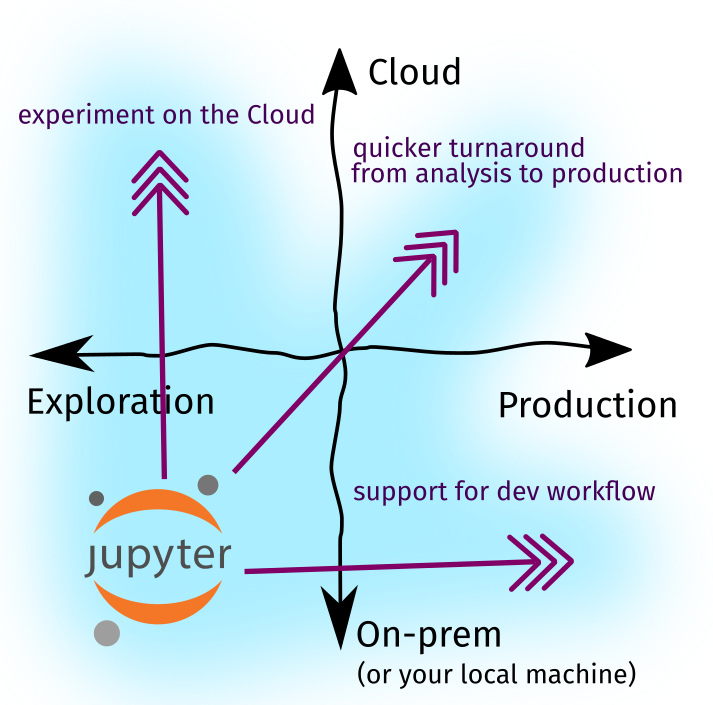
趋向“云优先”的环境意味着我们可以借助更强大的机器来执行基于notebook的任务。例如,将项目放到服务器上,就能够在远程运行Jupyter,这个远程服务器允许做各项相关环境配置。另一方面,生产工作的日益流程化为我们提供了一系列工具,使我们能够用基于Jupyter的工具完成开发工作。我将在本文的下一部分展示更多这样的工具。
最后,请注意,工具的增长并不依赖于单个实体或组织。正如我们稍后将看到的,填补这些空白的可能是贡献第三方插件的个人或组织。
结论
在本系列的第一部分中,我们研究了数据科学领域的两个驱动因素:(1)云计算技术,(2)不断增长的生产需求。我们看到Jupyter只占这个生态系统的一小部分。也就是说,Jupyter生态系统经常用于探索(而不是生产),只在本地机器上运行(而不是在云端)。
然后,使用相同的框架,我们确定了导致变化的三种力量,它们使Jupyter生态系统得以发展。这些力量可能促进了新工具、插件和产品的开发,以满足实际需求。
在本系列的下一部分中,我将讨论如何使用Jupyter来应对这些变化。我将介绍一些工具和工作流程,它们在日常工作和辅助项目中成为我的助力。敬请关注。
原文链接:https://ljvmiranda921.github.io/notebook/2020/03/06/jupyter-notebooks-in-2020/
搜索技术问答的公众号:老齐教室
在公众号中回复:老齐,可查看所有文章归类。
若你觉得我的文章对你有帮助,欢迎点击上方按钮对我打赏

关注微信公众号,读文章、听课程,提升技能